Running a tool on a CLC Server
When you launch an analysis from a Workbench that is logged into a CLC Server, you are offered the choice of where the analysis should be run (figure 13.6).
- Workbench Run the analysis on the computer the CLC Workbench is running on.
- CLC Server Run the analysis on a CLC Server single server, or on a job node if job nodes have been configured.
- Grid via CLC Server Submit the job to the grid, so the analysis will be done on a grid node. This option is available if the CLC Server has been configured with at least one grid preset. When more than one grid preset is available, the one to use should be selected from the drop down list in this section.
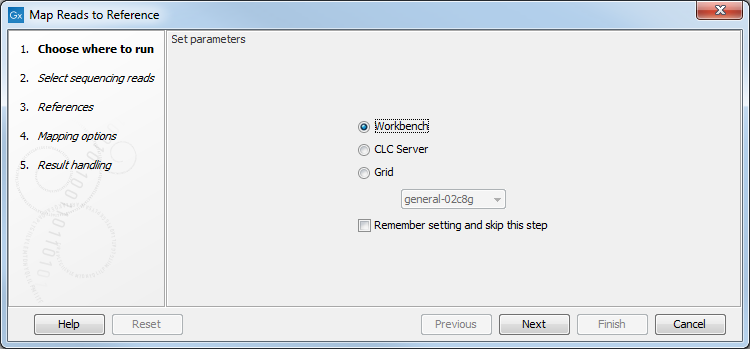
Figure 13.6: When logged into the CLC Server, you can select where a job should be run.
You can check the Remember setting and skip this step option if you wish to always use the selected option when submitting analyses. If you select this option but later change your mind, just start up an analysis and click on the Previous button to open these options again.
Most wizard steps for launching a job on a CLC Workbench or on a CLC Server are the same. There are two minor differences when launching jobs to run on a CLC Server: results are always saved, and a log of the job is always created and saved alongside the results.
Data access: When you run a job on a CLC Server, you will generally only be able to select data from and save results to areas known to the CLC Server. With default server settings, you will not be able to upload data from your local system. Your server administrator can enabled this if they wish. See the CLC Server manual for further details.
Disconnecting from the CLC Server: Once the job has been submitted, you can disconnect from the CLC Server if you wish, or close the CLC Workbench entirely. Exception: If you are importing data from the local file system, you must wait until the data has been imported before disconnecting. A notification about server jobs that finished is presented the next time you log in to the CLC Server. See Processes tab and Status bar.