Dynamic motifs
In the Side Panel settings of a sequence that is open for viewing, there is a Motifs palette (figure 18.23). Using these options, motifs can be added to or removed from the list, as well as moved up and down in the list. All listed motifs are searched for, and the number of instances found is reported in brackets by the motif name.
If the box by a particular motif is checked, that motif will be highlighted on the sequence itself (figure 18.24). By default, a motif is shown as a faded arrow, where the direction of the arrow indicates the strand of the motif. Hovering the mouse cursor over a motif on the sequence reveals information about the motif ( figure 18.25).
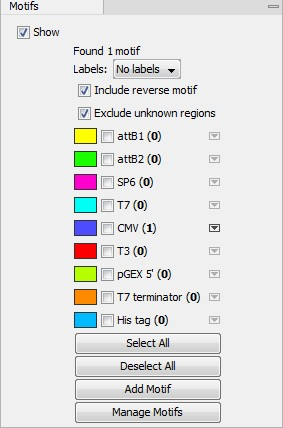
Figure 18.23: The Motifs palette of the Side Panel of an open sequence. A single instance of the CMV motif has been detected.
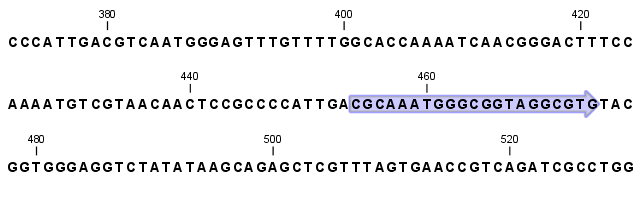
Figure 18.24: When the box next to a motif type is checked, any instances of that motif in a sequence will be highlighted in the view.

Figure 18.25: Hover the mouse cursor over a motif region on the sequence to reveal a tool tip with information about the motif.
To add Labels to the motif, select the Flag or Stacked option. They will put the name of the motif as a flag above the sequence. The stacked option will stack the labels when there is more than one motif so that all labels are shown.
Below the labels option there are two options for controlling the way the sequence should be searched for motifs:
- Include reverse motifs. This will also find motifs on the negative strand (only available for nucleotide sequences)
- Exclude matches in N-regions for simple motifs. The motif search handles ambiguous characters in the way that two residues are different if they do not have any residues in common. For example: For nucleotides, N matches any character and R matches A,G. For proteins, X matches any character and Z matches E,Q. Genome sequence often have large regions with unknown sequence. These regions are very often padded with N's. Ticking this checkbox will not display hits found in N-regions and if a one residue in a motif matches to an N, it will be treated as a mismatch.
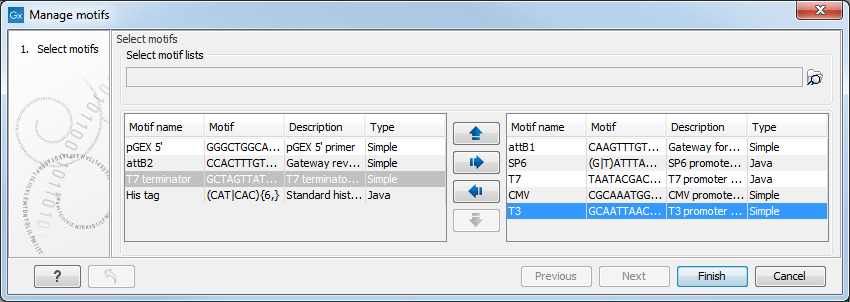
Figure 18.26: Managing the motifs to display
At the top, select a motif list by clicking the Browse (![]() ) button. When the motif list is selected, its motifs are listed in the panel in the left-hand side of the dialog. The right-hand side panel contains the motifs that will be listed in the Side Panel when you click Finish.
) button. When the motif list is selected, its motifs are listed in the panel in the left-hand side of the dialog. The right-hand side panel contains the motifs that will be listed in the Side Panel when you click Finish.
See section The Motif Search tool for a non-interactive option for detecting motifs.