De Novo Assembly output
Simple contigs
The output is a sequence list of the contigs generated (figure 36.20), that can also be seen as a table and an annotation table as described for the stand-alone read mapping described above.
Figure 36.20: A de novo assembly read mapping seen as annotation table.
Stand-alone mapping
The de novo assembly is followed by a step where the reads used to generate the contigs are mapped against the contigs, using them as reference.
This output is called assembly and opens as a table listing all contigs as seen in figure 36.21.
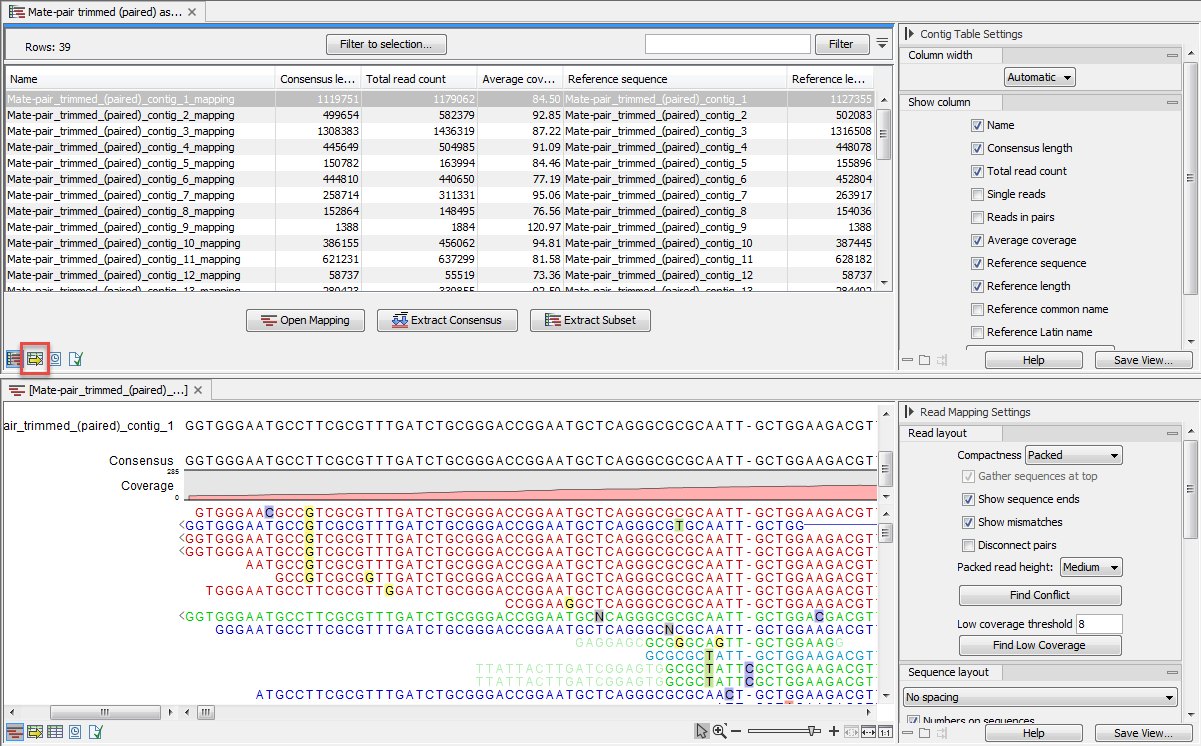
Figure 36.21: A de novo assembly read mapping.
The information included in the table is:
- Name. When mapping reads to a reference, this will be the name of the reference sequence.
- Consensus length. The length of the consensus sequence. Subtracting this from the length of the reference will indicate how much of the reference that has not been covered by reads.
- Total read count. The number of reads. Reads with multiple hits on different reference sequences are placed according to your input for Non-specific matches
- Single reads and Reads in pair. Total number of reads, single and/or in pair.
- Average coverage. This is simply summing up the bases of the aligned part of all the reads divided by the length of the reference sequence.
- Reference sequence. The name of the reference sequence.
- Reference length. The length of the reference sequence.
- Reference common name and Reference latin name. Name, common name and Latin name of each reference sequence.
At the bottom of the table there are three buttons that can be used to open or extract sequences. Select the relevant rows before clicking on the buttons:
- Open Mapping. Opens the read mapping for visual inspection. You can also open one mapping simply by double-clicking in the table.
- Extract Consensus/Contigs. For de novo assembly results, the contig sequences will be extracted. For results when mapping against a reference, the Extract Consensus tool will be used (see Extract consensus sequence).
- Extract Subset. Creates a new mapping table with the mappings that you have selected.
Double clicking on a contig name will open the read mapping in split view.
It is possible to open the assembly as an annotation table (using the icon highlighted in figure 36.21). The annotations available in the table are the following (see figure 36.22):
- Alternatives Excluded. More than one path through the graph was possible in this region but evidence from paired data suggested the exclusion of one or more alternative routes in favour of the route chosen.
- Contigs Joined. More than one route was possible through the graph such that an unambiguous choice of how to traverse the graph cannot by made. However evidence from paired data supports one of these routes and on this basis, this route is selected (and other routes excluded).
- Scaffold. The route through the graph is not clear but evidence from paired data supports the connection of two contigs. A single contig is then reported with N characters between the two connected regions. This entity is also known as a scaffold. The number of N characters represents the expected distance between the regions, based on the evidence the paired data.
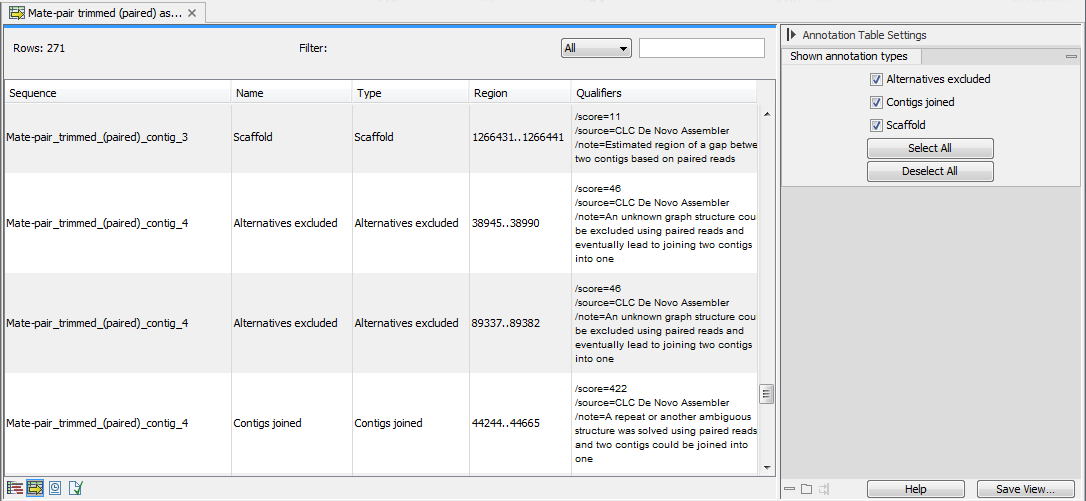
Figure 36.22: A de novo assembly read mapping seen as annotation table.
Using the menu in the right end side panel, it is possible to select only one type of annotations to be displayed in the table.
De Novo Assembly report
A de novo assembly report looks like the one shown in figure 36.23.
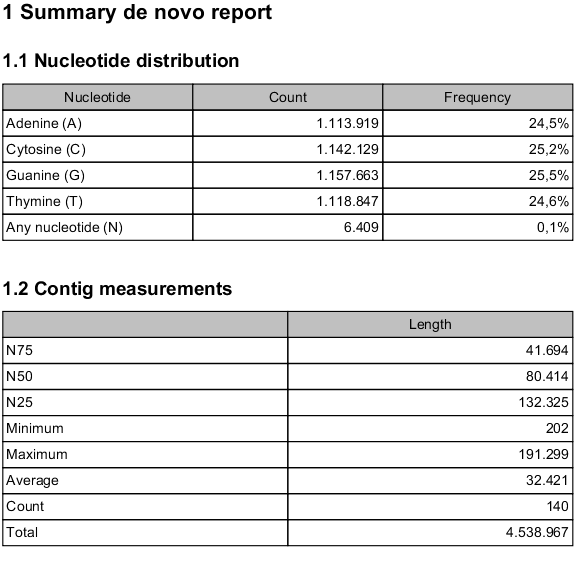
Figure 36.23: Creating a de novo assembly report.
The report contains the following information when both scaffolding and read mapping is performed:
- Nucleotide distribution
- This includes Ns when scaffolding has been performed.
- Contig measurements
- This section includes statistics about the number and lengths of contigs. When scaffolding is performed and the update contigs option is not selected, there will be two separate sections with these numbers: one including the scaffold regions with Ns and one without these regions.
- N25, N50 and N75 The N25 contig set is calculated by summarizing the lengths of the biggest contigs until you reach 25 % of the total contig length. The minimum contig length in this set is the number that is usually used to report the N25 value of a de novo assembly. The same goes with N50 and N75 which are the 50 % and 75 % of the total contig length, respectively.
- Minimum, maximum and average This refers to the contig lengths.
- Count The total number of contigs.
- Total The number of bases in the result. This can be used for comparison with the estimated genome size to evaluate how much of the genome sequence is included in the assembly.
- Accumulated contig lengths
- This shows the summarized contig length on the y axis and the number of contigs on the x axis, with the biggest contigs ranked first. This answers the question: how many contigs are needed to cover e.g. half of the genome.
- Summary statistics
- Gives the count, average length and total bases amount for all reads, matched and non-matched reads, contigs, reads in pairs, and broken paired reads.
- Distribution of read length
- For each sequence length, you can see the number of reads and the distribution in percent. This is mainly useful if you don't have too much variance in the lengths as in Sanger sequencing data for example.
- Distribution of matched read length
- Equivalent to the above, except that this includes only the reads that have been matched to a contig.
- Distribution of non-matched read length
- Shows the distribution of lengths of the unmapped sequences.
- Paired reads distance distribution
- Shows the distribution of paired reads distances.
For a more detailed report, use the QC for Read Mapping tool, and see the description of the report in see Detailed mapping report.