Mapping output
Click Next lets you choose how the output of the mapping should be reported (see
figure 25.4).
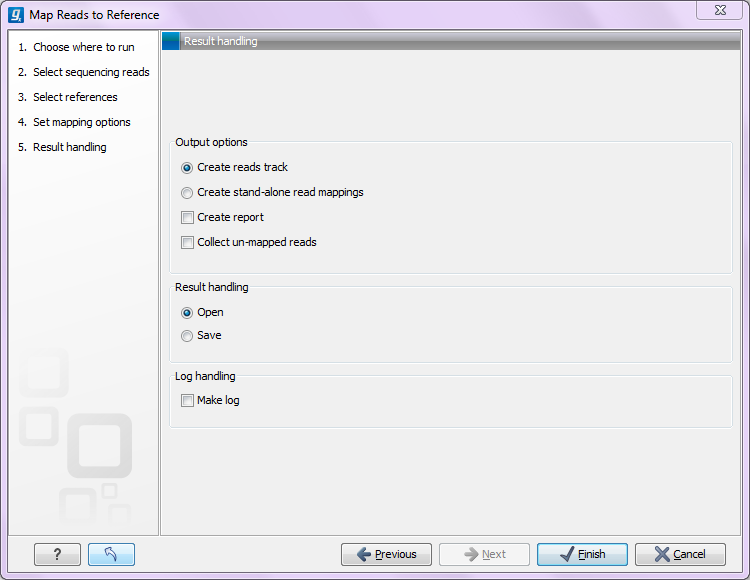
Figure 25.4: Mapping output options.
At the top, you can choose between if the read mapping should be created as a track or as a stand-alone read mapping:
- Reads track
- A reads track is very lean: it only consists of the reads themselves. There is no reference nor consensus sequence. This kind of output is useful when you are working with tracks in general and especially for resequencing purposes this is recommended. Read more about resequencing and tracks.
- Stand-alone read mapping
- This output is more elaborate than the reads track and includes the full reference sequence (including annotations) and a consensus sequence is created as part of the output. Furthermore, the possibilities for detailed visualization and editing are richer than for the reads track (see View and edit read mapping). The weak side of the stand-alone read mapping is that it copies all the information from the reference sequence which can take up a lot of disk space, and second that it does not lend itself to comparative analyses. If you wish to compare e.g. SNPs from one sample to another sample, or against a database of variants, this calls for using a reads track instead. Note that if you have used multiple reference sequences as input, a read mapping table is created (see Mapping table).
In addition to the main output, you have two auxiliary output options:
- Create report. This will generate a summary report as described in Summary mapping report.
- Collect un-mapped reads. This will collect all the reads that could not be mapped to the reference into a sequence list (there will be one list of unmapped reads per sample, and for paired reads, there will be one list for intact pairs and one for single reads where the mate could be mapped).
Finally, you can choose to save or open the results, and if you wish to see a log of the process (see how to handle the results).
Clicking Finish will start the mapping.