Analyze QIAseq xHYB Mycobacterium Tuberculosis Panel Data (Human host)
This workflow has been incorporated into the workflow Analyze QIAseq xHYB Mycobacterium tuberculosis and NTM-ID Panel Data (Human host). Please run that workflow instead.
This workflow has been deprecated and will be retired in a future version of the software. It has been moved to the Legacy Template Workflows (![]() ) folder of the Toolbox, and its name has "(legacy)" appended to it. If you have concerns about the future retirement of this workflow, please contact QIAGEN Bioinformatics Support team at ts-bioinformatics@qiagen.com.
) folder of the Toolbox, and its name has "(legacy)" appended to it. If you have concerns about the future retirement of this workflow, please contact QIAGEN Bioinformatics Support team at ts-bioinformatics@qiagen.com.
The Analyze QIAseq xHYB Mycobacterium Tuberculosis Panel Data (Human host) (legacy) template workflow performs spoligotyping for lineage detection and identifies high-frequency antimicrobial drug resistance variants. It is suitable for analysis of samples from human hosts generated with the QIAseq xHYB Mycobacterium tuberculosis Panel. Optionally, the workflow also detects and types Mycobacteriaceae, if the QIAseq xHYB NTM-ID Panel was used in conjunction with the QIAseq xHYB Mycobacterium tuberculosis Panel.
To analyze samples not from human hosts, you can create a copy of the workflow and edit it to fit your specific application, see Template workflows. Since the workflow element Map Reads to Human Control Genes is relevant for human data only, you should delete this. In addition, if a host genome is not relevant for you application, open the Taxonomic Profiling workflow element, and uncheck Filter host reads.
Once the workflow copy is customized, you can install it to make it available from under the Workflows menu (see Workflow installation).
To run the workflow using a variant database other than the default one, you need to modify the workflow elements where the database name appears as a column header, such as Filter for WHO variants and WHO variant associated with resistance.
QIAGEN Reference Data Set
The QIAseq xHYB Mycobacterium tuberculosis Panel Reference Data Set contains reference data relevant for this template workflow. It includes the Mycobacterium tuberculosis reference genome H37Rv and the WHO Mycobacterium tuberculosis variant database based on the WHO Mycobacterium tuberculosis mutation catalogue (see Reference Data Elements). Like the template workflow, the reference data set is designed for human samples. It contains both a human host taxonomic profiling index and a sequence list with human control genes for use in the workflow step Map Reads to Human Control Genes.
For performing Mycobacteriaceae typing analysis a version of the QIAseq xHYB Mycobacterium tuberculosis Panel Reference Data Set, which contains the hsp65 reference database needed, is also available (for more, see Mycobacteriaceae typing analysis).
Data in the QIAseq xHYB Mycobacterium tuberculosis Panel set not already downloaded can be downloaded during the launch of the workflow. It can also be downloaded, as well as managed, using the Reference Data Manager, which can be opened by clicking on the Manage Reference Data (![]() ) button in the Toolbar. Click on the QIAGEN Sets Reference Data Library tab in the Reference Data Manager and search for the set by entering terms from its name in the search field.
) button in the Toolbar. Click on the QIAGEN Sets Reference Data Library tab in the Reference Data Manager and search for the set by entering terms from its name in the search field.
For analysis of samples not from human hosts: If a non-human host is relevant for your application, you can create a host taxonomic profiling index from your host reference genome using Create Taxonomic Profiling Index, see Create Taxonomic Profiling Index.
The workflow analysis
The raw Mycobacterium tuberculosis whole genome sequencing reads are trimmed for low quality, read-through adapter sequences, and G homopolymers. Trimmed reads are used as input for the separate spoligotyping analysis.
In the Taxonomic Profiling step, reads that map to the human host index are filtered. As a quality control step, these reads are subsequently mapped to the human control genes defined for the panel. In addition to human reads, reads identified as belonging to taxonomies other than Mycobacterium tuberculosis are excluded from downstream analysis.
The remaining reads are mapped to the Mycobacterium tuberculosis reference genome, and variants are called from this read mapping. The reference genome may differ from the lineage reported by the spoligotyping step. Using the same reference genome for mapping and variant calling across samples ensures comparability of variants and facilitates alignment with variant databases, such as the WHO Mycobacterium tuberculosis mutation catalogue, which are based on a specific genome. Variant calling is optimized for calling resistance in the dominant strain of an infection: variants with frequency beneath 50% will typically not be reported.
Detected variants are compared to the WHO drug resistance variant database and annotated with drug resistance information. Larger InDels that cannot be matched to the variant database exactly (e.g. whole-gene deletions), but that overlap with possible resistance InDels, are reported as candidate InDels and annotated with information from all resistance InDels that they overlap (for more, see WHO Candidate InDels).
The analysis can also detect and type Mycobacteriaceae (for more, see Mycobacteriaceae typing analysis).
Launching the workflow
Before launching the workflow, make sure to download the QIAseq xHYB Mycobacterium tuberculosis Panel reference data set.
The Analyze QIAseq xHYB Mycobacterium Tuberculosis Panel Data (Human host) (legacy) workflow is available at:
Workflows | Template Workflows (![]() ) | Legacy Template Workflows (
) | Legacy Template Workflows (![]() ) | Analyze QIAseq xHYB Mycobacterium Tuberculosis Panel Data (Human host) (legacy) (
) | Analyze QIAseq xHYB Mycobacterium Tuberculosis Panel Data (Human host) (legacy) (![]() )
)
Launch the workflow and step through the wizard.
- Select whether to perform Mycobacteriaceae typing analysis. If the QIAseq xHYB NTM-ID Panel was used in conjunction with the QIAseq xHYB Mycobacterium tuberculosis Panel, select "Yes" (for more, see Mycobacteriaceae typing analysis).
- Select the sequence list(s) containing the sample reads. If selecting multiple inputs from different samples, check the Batch option, see Running workflows in batch mode.
- Select a reference data set or select "Use specified data elements". The latter runs the workflow using default elements, which can be viewed by clicking the "workflow roles" text just above the option.
- If Batch was checked in step 1, choose whether batch units should be defined based on organization of the input data, or by provided metadata. In the next step, review the batch units resulting from your selections above.
- Specify the spoligotyping settings (figure 21.1). Using the default values is usually sufficient, but we recommend taking a look at the spoligotyping report afterwards to make sure the results are as expected.
- If you selected "Yes" for performing Mycobacteriaceae typing analysis, the parameters for filtering references can be changed. This might be necessary if the expected Mycobacteriaceae species is present in the sample at a very low abundance. The default settings are expected to work in most cases. For more information about the filters, see Find Best References using Read Mapping.
- Finally, select a location to save outputs to.
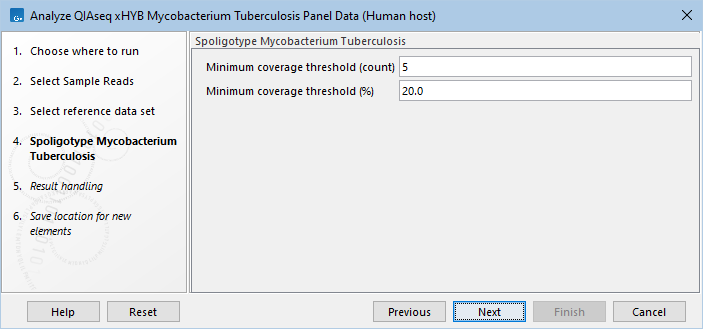
Figure 21.1: Select the minimum threshold settings for spoligotyping.
Workflow outputs and how to interpret
The outputs provided by the workflow are:
- QC & Reports. Folder containing the individual reports generated during the analysis.
- All reports from the sample report are found here in their full length.
- Tracks. Folder containing various tracks.
- Genome, Gene and CDS tracks based on the Mycobacterium tuberculosis reference used.
- Human_control_genes_read_mapping. Track to see mapping of the human host reads to the control genes.
- Read_mapping. Reads track of the sample reads mapping to the reference genome.
- Amino_acid_track. Track to see amino acids and potential changes in coding sequences of the reference genome.
- WHO_mycobacterium_tuberculosis_variant_database_v1.0 (filtered). The WHO resistance database, filtered to only contain Insertions and Deletions overlapping with candidate InDels (for more, see WHO Candidate InDels).
- Variants. Folder containing all the variant tracks generated during the analysis.
- Raw_variants. Variant track containing all raw variants detected by Fixed Ploidy Variant Detection i.e., before adjusting with Join Nearby Variants and annotating.
- Filtered_InDels. InDels detected by InDels and Structural Variants that were not already present in the "Raw_variants" track. Only InDels with a variant ratio over 0.5 are reported. These InDels are later merged with the other variants and included in the "Annotated variants" track.
- WHO_variants_detected. Variant track containing only variants from the WHO resistance database.
- Novel_variants_detected. Variant track containing only variants that are not graded by the WHO.
- WHO_candidate_InDels. Annotation track containing insertions, deletions and "complexes" that may correspond to a WHO-graded variant, but which it was not possible to match to the resistance database exactly (for more, see WHO Candidate InDels).
- Genome Browser. A track list containing the reference genome, gene, CDS, read mapping, variant, candidate InDels, and amino acid changes tracks.
- QIAseq xHYB Mycobacterium Tuberculosis Analysis Report. Sample report containing results of the analysis. The sample report is curated to contain the most important information for analysis interpretation, but all full reports can be found in the QC & Reports folder.
- Annotated variants. Variant track containing all detected variants and non-candidate InDels after readjustment and annotated with WHO resistance, amino acid changes and gene information.
If you selected "Yes" for performing Mycobacteriaceae typing analysis, some additional outputs are provided:
- NTM-ID Panel Analysis. (Only if a positive result was detected). Folder containing results from the analysis.
- Mycobacteriaceae reads. Sequence lists (single and paired) containing reads from the input that mapped to the hsp65 references before refinement of references.
- Mycobacteriaceae read mapping. Reads track of the reads mapped to the final hsp65 references.
- QIAseq xHYB NTM-ID Analysis Report. The report is curated to contain the most important information for analysis interpretation. All full reports are linked throughout this report or can be found in the QC & Reports folder.
The report icon will be colored based on whether Mycobacteriaceae was detected (for more, see Mycobacteriaceae typing analysis):- A green dot on the report icon indicates detection of at least one Mycobacteriaceae species.
- A red dot on the report icon indicates no detection of Mycobacteriaceae species.
The sample report "QIAseq xHYB Mycobacterium Tuberculosis Analysis Report" is the main output of the workflow. This allows for easy overview of the analysis results, both in terms of quality control and detected drug resistance for the sample. An example of the report can be seen in figure 21.2.
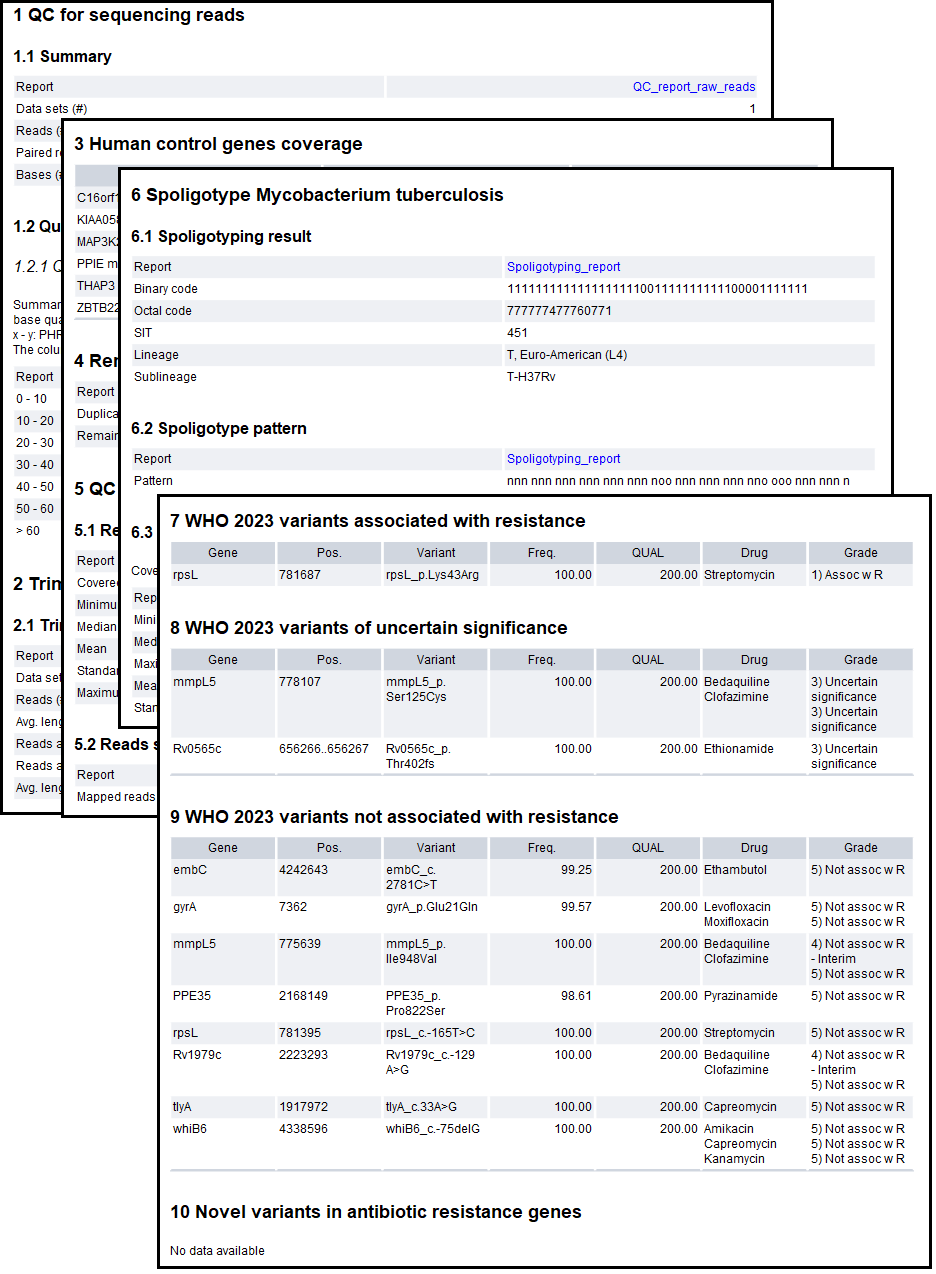
Figure 21.2: An example report from the Analyze QIAseq xHYB Mycobacterium Tuberculosis Panel Data (Human host) (legacy) workflow.
The report contains the following sections:
- Sections 1-5 contain quality metrics for the analysis:
- QC for sequencing reads. A summary of the number of raw reads and their quality. If the reads are of too low quality, the results may be unreliable.
- Trim reads. A summary of the read trimming. If the percentage of reads after trim is low or the average read length after trimming is considerably lower than before trimming, it may be a sign that something is wrong with the sample reads.
- Human control genes coverage. A summary of the host reads mapping to the human control genes. The coverage can be low, but there should be some reads mapping to the genes. If not, something may have gone wrong during the sample prep, or the sample was not made with the QIAseq xHYB Mycobacterium tuberculosis Panel.
- Remove duplicate mapped reads. A high percentage of duplicates may indicate that the sample contains little gDNA.
- QC for read mapping. For the QIAseq xHYB Mycobacterium tuberculosis panel, the coverage percentage should be close to 100%. Also, most of the reads after trimming (see Reads after trim in the Trim reads section) should be mapped. If this is not the case, there may have been an issue with the sample prep.
- Sections 6-11 contain lineage and variant results from the analysis:
- Spoligotype Mycobacterium tuberculosis. Results of spoligotyping. This reports on the detected SIT, lineage, sublineage, and spoligotype pattern. It can be a good idea to take a look at the coverage plot in the full spoligotyping report (/QC & Reports/Spoligotyping_report), to ascertain whether the minimum threshold has been correctly set. For additional information about the spoligotype report content, see Spoligotype Mycobacterium Tuberculosis output.
- WHO 2023 variants associated with resistance. Variants detected in the sample that have been graded "1)" or "2)" for at least one drug by the WHO. As variants can be graded for multiple drugs with different grades, this section may contain grades of "3)" and higher as well. For information about WHO grading, see Reference Data Elements.
- WHO 2023 variants of uncertain significance. Variants detected in the sample that have been graded "3)" for at least one drug by the WHO, but not "1)" or "2)". As variants can be graded for multiple drugs with different grades, this section may contain grades of "4)" and higher as well.
- WHO 2023 variants not associated with resistance. Variants detected in the sample that have only been graded "4)" or "5)" by the WHO.
- WHO 2023 candidate InDels. InDels detected in the sample that overlap one or more WHO-graded InDels (for more, see WHO Candidate InDels).
- Novel variants in antibiotic resistance genes. Variants detected in the sample, but that are not graded by the WHO. The report only contains variants in known resistance genes, and excludes variants in protein-coding regions that result in synonymous mutations. To view all detected novel variants, look at the "/Variants/Novel_variants_detected" variant track.
The variant table reports contain the following columns:
- Gene. For WHO variants, this is the gene with which the variant is associated. For Novel variants, it is the gene in which the variant is located.
- Pos.. The genomic position of the variant within the reference genome.
- Variant. (Only WHO variants). The name(s) of the variant as given by WHO. The name consists of the gene in which the variant is located, along with the corresponding position and change, either as a nucleotide or amino acid change.
- AA change. (Only Novel variants). This describes the change on the protein level. For example, single amino-acid changes caused by SNVs are listed as p.Gly261Cys, denoting that in the protein sequence (hence the "p.") the Glycine at position 261 is changed into Cysteine. Frame-shifts caused by nucleotide insertions and deletions are listed with the extension fs, for example p.Pro244fs denoting a frameshift at position 244 coding for Proline. For further details about HGVS nomenclature as relates to proteins, see http://varnomen.hgvs.org/recommendations/protein/.
- Freq.. The number of reads supporting the allele divided by the number of reads covering the position of the variant. Note that variants with frequency beneath 50% will typically not be reported.
- QUAL. Measure of the significance of a variant, i.e., a quantification of the evidence (read count) supporting the variant, relative to the coverage and what could be expected to be seen by chance, given the error rates in the data. For additional information, see Variant tracks.
- Drug. (Only WHO variants). The antimicrobial resistance drug(s) for which the variant is graded.
- Grade. (Only WHO variants). The grade of drug resistance determined for the variant.
The candidate InDels table report contains the following unique columns (for more, see WHO Candidate InDels):
- Variant type. The type of variant detected, either "Deletion", "Insertion" or "Complex". A "Complex" variant indicates that more than two breakpoints give rise to the structural variant.
- Ratio. Ratio of reads calculated as the sum of the 'Non perfect mapped' reads for the breakpoints used to infer the InDel, divided by the sum of the 'Non perfect mapped' and 'Perfect mapped' reads for the breakpoints used to infer the InDel. Note that variants with ratio beneath 50% will not be reported.
- Evidence. The mapping evidence on which the call of the InDel was based (see Theoretically expected structural variant signatures).
- Candidate Drug(s). The antimicrobial resistance drug(s) for which variants overlapping with the candidate InDel are graded.
- Candidate Grade(s). The grade(s) of drug resistance determined for variants overlapping with the candidate InDel.
If no variants are detected in a section of the report, it will say "No data available".
For more info on the WHO variant database, including the resistance grades, see Reference Data Elements.
WHO 2023 candidate InDels
Candidate InDels are structural variants that overlap, but do not exactly match, a WHO-graded variant. These include large deletions that may cause loss of function of a resistance-associated gene. Only deletions that overlap with a WHO deletion, and insertions that overlap with a WHO insertion are included. Complexes are included if they overlap with either.
Candidate InDels are called by InDels and Structural Variants as Deletions, Insertions or Complexes. A complex is usually called in regions with more than 2 signature breakpoints (see Structural Variants and InDels output).
As candidate InDels may overlap with many resistance-associated variants, these are not listed individually. Instead the "Candidate Drug(s)" column includes all possible drugs to which the variants may confer resistance. Similarly, the "Candidate Grade(s)" column includes all possible grades of resistance associated with those variants. To avoid redundancy, each drug and grade will only be reported once in the column, even if multiple variants are associated with that drug and grade.
A candidate InDel is not a guarantee of resistance or susceptibility, but an indicator that one should take a closer look at that location in the read mapping, to evaluate whether the variant is of interest.
A good way to investigate a candidate InDel further is to open up the "Genome Browser" track list output from the analysis and zoom into the candidate InDel's location. In figure 21.3 it is clear from the read mapping that a large deletion is present where the "Complex" is called.
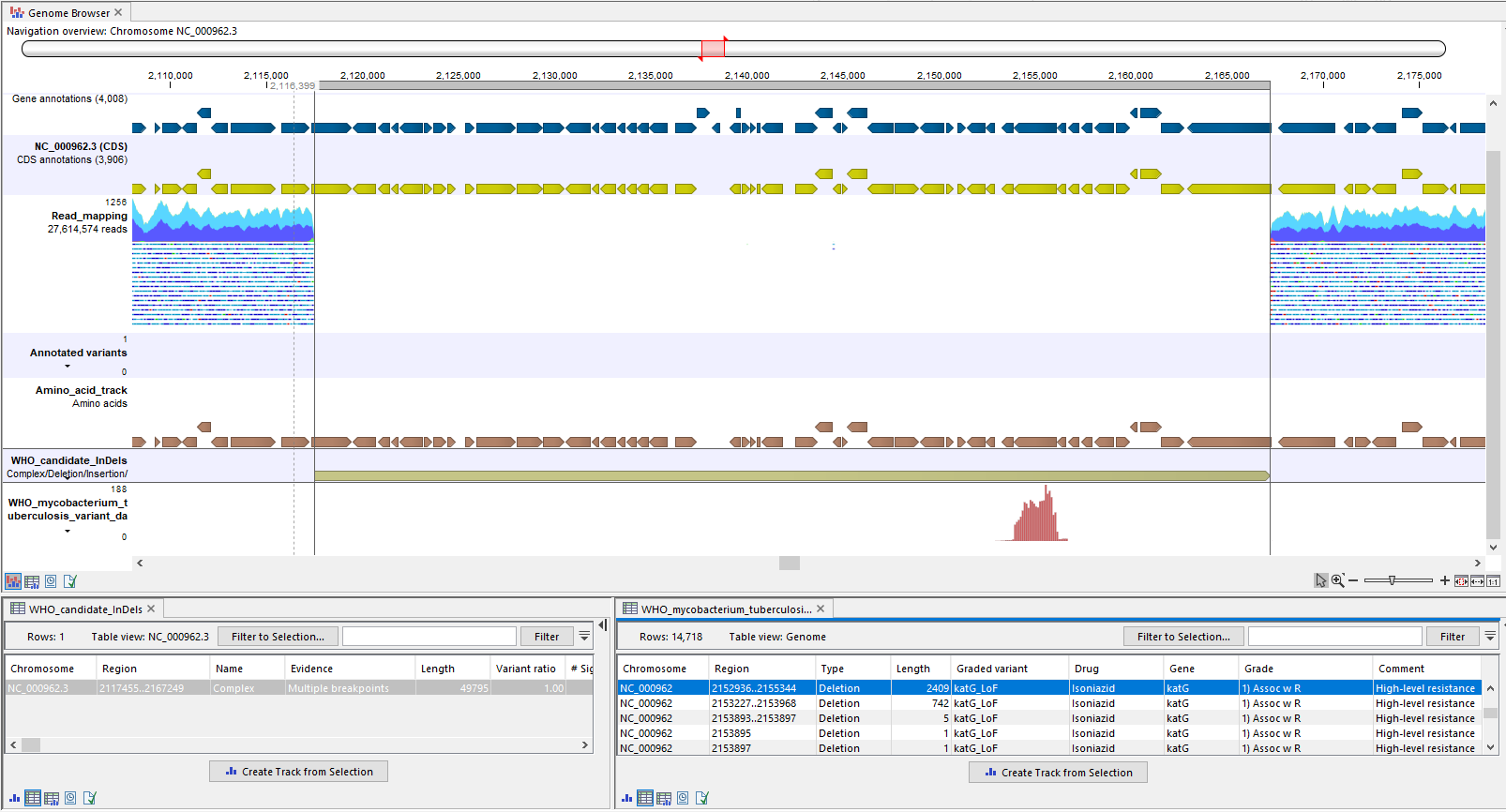
Figure 21.3: A candidate complex called in a region of the genome where the read mapping clearly lacks coverage, indicating that the complex is a deletion. In the filtered WHO resistance database track (bottom), it can be seen that the candidate complex, now confirmed to be a deletion, overlaps with multiple large WHO LoF deletions.
Candidate InDels are annotated with both WHO insertions and deletions, so it is necessary to take a closer look at the variants to determine whether candidate drug resistance from the report is supported. The "WHO_mycobacterium_tuberculosis_variant_database_v1.0 (filtered)" track in the Genome Browser can help to investigate whether the InDel overlaps with a meaningful WHO variant. In figure 21.3 the candidate deletion overlaps with multiple WHO loss of function deletions, which confer resistance to the drug Isoniazid. It can be inferred that a large deletion will confer similar resistance (see also pages 88 and 102 about "feature_ablation" in [WHO, 2023]).
Mycobacteriaceae typing analysis
The Mycobacteriaceae typing analysis is intended for samples where the QIAseq xHYB NTM-ID Panel was used in conjunction with the QIAseq xHYB Mycobacterium tuberculosis Panel. It performs the analysis in the same way as the Analyze QIAseq xHYB NTM-ID Panel Data (Human host) (legacy) template workflow. A description of the analysis is available under The workflow analysis.
The reads used as input for the Mycobacteriaceae analysis in this workflow, are extracted from the hsp65 gene region of the H37Rv read mapping. Due to the high level of similarity between hsp65 genes from different Mycobacteriaceae species, reads are expected to map to this region, even if they don't come from H37Rv.
The "QIAseq xHYB NTM-ID Analysis Report" report contains the following sections:
- Summary. A summary of the QC summary item "Percentage reads mapped to reference" and whether it passed (green) or failed (red).
- Find best references using read mapping. Contains a summary of how many of the input reads mapped to the hsp65 references and how many were unmapped. These are the mapping statistics before refinement of the references, and may not match the number of reads mapped to the reference(s) in the following sections. To see more details of the results prior to refinement, see the "Find_best_reference_report" in the "QC & Reports" folder.
- QC for Mycobacteriaceae mapping. (Only if a positive result was detected). Contains the name of the reference(s) detected after refinement of references and mapping statistics for the reads mapped to them. The bottom of Workflow outputs and how to interpret contains details about the columns.