Download Custom Microbial Reference Database
The Download Custom Microbial Reference Database tool allows you to create a custom database from taxonomies or NCBI assembly IDs. The tool outputs a single sequence list.
To run the tool, go to:
Tools | Microbial Genomics Module (![]() ) | Databases (
) | Databases (![]() ) | Taxonomic Analyses (
) | Taxonomic Analyses (![]() ) | Download Custom Microbial Reference Database (
) | Download Custom Microbial Reference Database (![]() )
)
Under Customize Database, select whether to include genomic and/or plasmid sequences (figure 16.2):
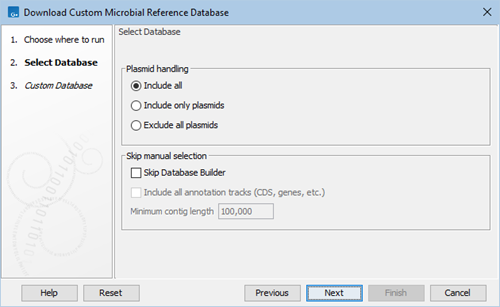
Figure 16.2: Select type of sequences to include and whether to skip the Database Builder.
- Include all. The database will contain both genomic and plasmid sequences.
- Include only plasmids. The database will contain only plasmid sequences.
- Exclude all plasmids. The database will not contain any plasmid sequences.
Choose whether you wish to skip manual selection:
- Skip Database Builder. If checked, a reference database with genomes matching the specified criteria will be downloaded once you click Finish from the next wizard step.
If left unchecked, clicking Finish will instead open the Database Builder from which you can manually select genomes for download, see Database Builder. Genomes that match the specified criteria will be pre-selected.
- Include all annotation tracks. Will include CDS, gene, etc. annotations in the downloaded database. The annotations are not needed for taxonomic profiling, but may be required for other applications such as creating MLST schemes.
- Minimum contig length. The minimum length of sequences to be included in the database.
Click Next to customize the database (figure 16.3):
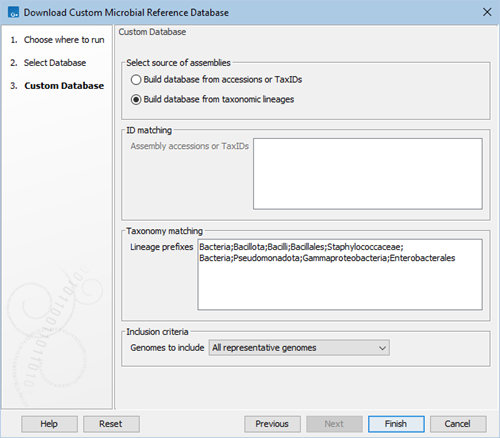
Figure 16.3: Specify accession or TaxIDs, or taxonomic lineages to include in the database.
- Select source of assemblies:
- Build database from accessions or TaxIDs. Enables the ID matching field, see below.
- Build database from taxonomic lineages. Enables the Taxonomic matching, see below.
- ID matching. Provide a list of GenBank or RefSeq assembly accessions, or NCBI TaxIDs or species TaxIDs (one per line) to be included in your database.
If using GenBank or RefSeq assembly accessions, the accessions must follow the assembly accession: 3 letter prefix, (GCA for GenBank assemblies or GCF for RefSeq assemblies) followed by an underscore and 9 digits. For example, GCA_000019425 for the assembly of the DH10B substrain of E. coli. If a version number is included, it will be ignored and the newest version downloaded. The assembly is always downloaded from GenBank.
The TaxID is the NCBI taxonomy identifier for the organism from which the genome assembly was derived. The species TaxID is the identifier for the species to which the organism belongs. For a given organism, TaxID and species TaxID will be identical unless the organism was reported at a strain or subspecies level.
- Taxonomy matching. Provide a list of taxonomic lineage prefixes (one per line) to include in your database. The lineages should follow the format of 7-step taxonomies. For example entering "Bacteria;Bacillota;Bacilli;Bacillales;Staphylococcaceae;" will include all genera and species genomes in the Staphylococcaceae family. Entering "Bacteria;Pseudomonadota;Gammaproteobacteria;Enterobacterales;" will include all family, genera and species genomes in the Enterobacterales order. The NCBI taxonomy is updated weekly. When searching you should use the updated taxonomy.
- Inclusion criteria:
- All reference genomes. All reference genomes in the chosen lineage(s) are included.
- All representative genomes. All representative genomes in the chosen lineage(s) are included.
- All reference and representative genomes. All reference and representative genomes in the chosen lineage(s) are included.
- All genomes. All genomes in the chosen lineage(s) are included.
- One per species. One reference is selected for each species in the chosen lineage(s). The chosen species representative is selected based on ranking with Reference genomes > Representative genomes > Complete genomes > Scaffolds > Contigs. When two or more references share the same rank, the reference with the longest chromosome is selected. Note species are identified using species TaxIDs. This means that assemblies with different species names but the same species TaxIDs are considered as one species.
- One per genus. One reference is selected for each genus in the chosen lineage(s). The chosen genus representative is selected based on ranking with Reference genomes > Representative genomes > Complete genomes > Scaffolds > Contigs. When two or more references share the same rank, the reference with the longest chromosome is selected.
Click Finish.
If Skip Database Builder was selected, all genomes matching the specified criteria will now be downloaded. If the enabled ID or Taxonomy matching field was left empty, no genomes will be downloaded.
If Skip Database Builder was left unchecked, a reference database is not downloaded right away. Instead, the Database Builder will open, see Database Builder.
Subsections