Extract reads based on overlap
This tool can be used to extract subsets of reads based on annotations. When extracting reads with a specific annotation, the annotation will function as a tag pulling out all the reads with the overlapping annotation (or, when handling paired read data, all the pairs of reads). To launch the tool, go to:
Toolbox | Track Tools (![]() ) | Annotate and Filter | Extract Reads Based on Overlap (
) | Annotate and Filter | Extract Reads Based on Overlap (![]() )
)
Read mapping tracks can be used as input (figure 22.37).
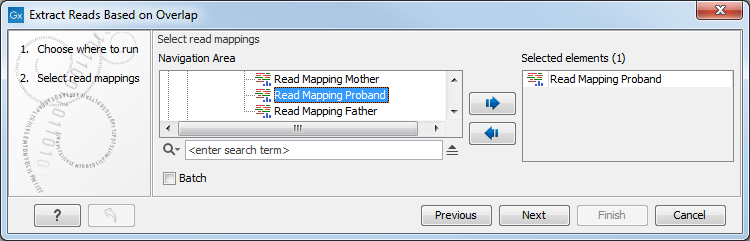
Figure 22.37: Select a read mapping. Only one read mapping can be selected at the time.
The next step is to select the annotated track(s) to be used for pulling out reads and specify which reads to include (figure 22.38). Note that it is also possible to select here a RNA-seq statistical comparison.
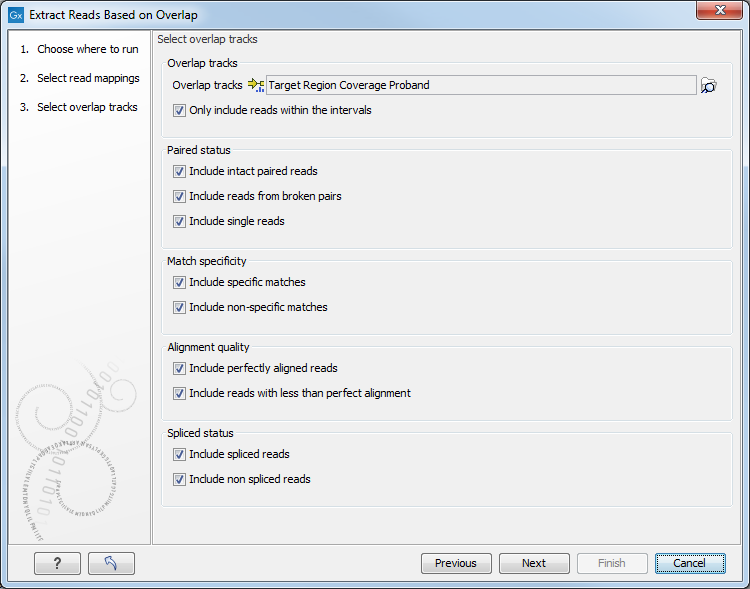
Figure 22.38: Select the track(s) containing the annotation(s) of interest. Multiple tracks can be selected at the same time.
The options in this wizard are:
- Overlap tracks
- $&bull#bullet;$
- Select the annotated track
- Only include reads within the intervals
- It is possible to select whether only reads within the intervals should be extracted, or whether reads continuing outside the annotated region should be extracted. The difference between the options can be seen in figure 22.39.
- Paired status
- Include intact paired reads
- When paired reads are placed within the paired distance specified, they will fall into this category. Per default, these reads are colored in blue.
- Include paired reads from broken pairs
- When a pair is broken, either because only one read in the pair matches, or because the distance or relative orientation is wrong, the reads are placed and colored as single reads, but you can still extract them by checking this box.
- Include single reads
- This will include reads that are marked as single reads (as opposed to paired reads). Note that paired reads that have been broken during assembly are not included in this category. Single reads that come from trimming paired sequence lists are included in this category.
- Match specificity
- Include specific matches
- Reads that only are mapped to one position.
- Include non-specific matches
- Reads that have multiple equally good alignments to the reference. These reads are colored yellow per default.
- Alignment quality
- Include perfectly aligned reads
- Reads where the full read is perfectly aligned to the reference sequence (or consensus sequence for de novo assemblies). Note that at the end of the contig, reads may extend beyond the contig (this is not visible unless you make a selection on the read and observe the position numbering in the status bar). Such reads are not considered perfectly aligned reads because they don't align in their entire length.
- Include reads with less than perfect alignment
- Reads with mismatches, insertions or deletions, or with unaligned nucleotides at the ends (the faded part of a read).
- Spliced status
- Include spliced reads
- Reads that are across an intron.
- Include non spliced reads
- Reads that are not across an intron.
Figure 22.38 shows two examples of output when the overlap track used as input was generated using the "Identify Graph Threshold Areas".
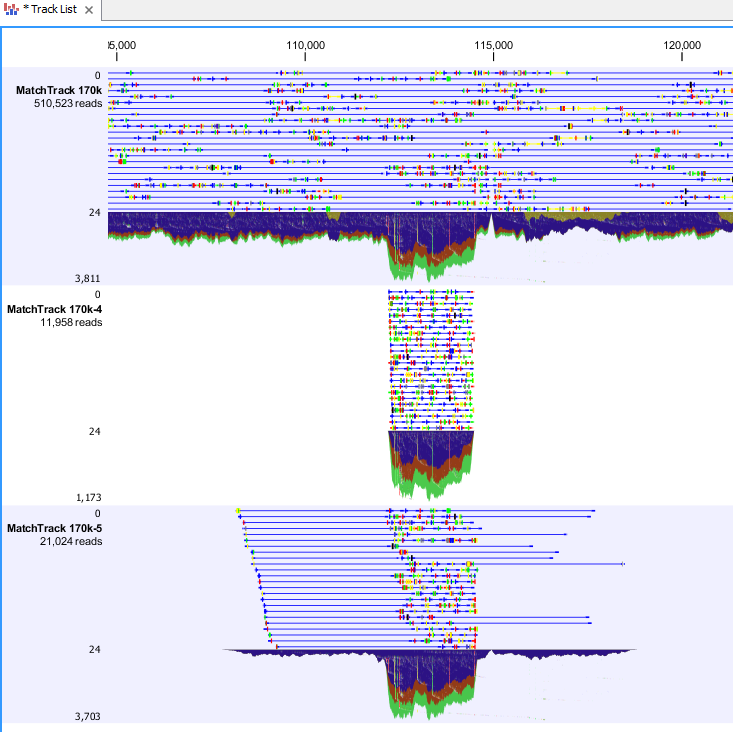
Figure 22.39: Output from Extract reads based on overlap. Top: The read mapping used as input. Middle: Output when "Only include reads within intervals" has been ticked. Bottom: Output when "Only include reads within intervals" has been deselected.