Illumina
The CLC Cancer Research Workbench supports data from Illumina's Genome Analyzer, HiSeq 2000 and the MiSeq systems. Choosing the Illumina import will open the dialog shown in figure 6.6.
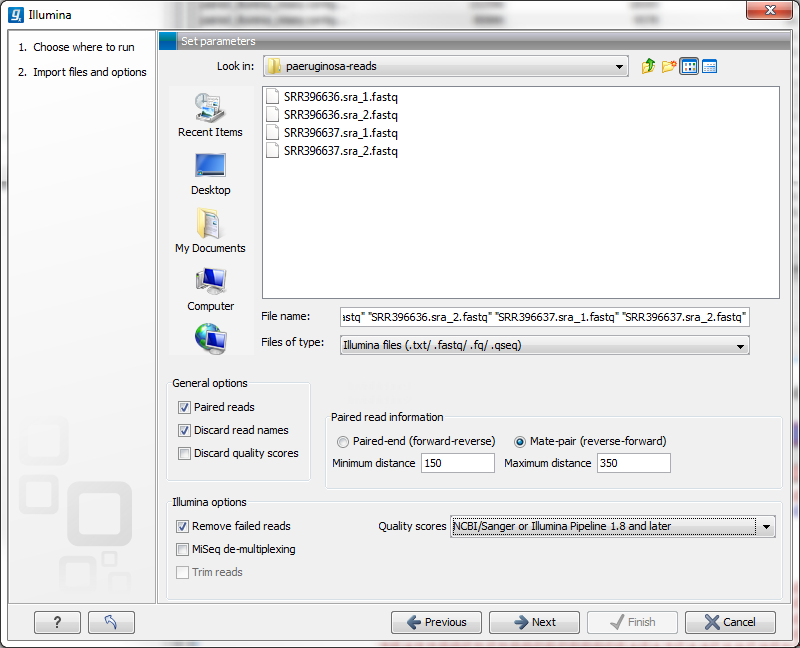
Figure 6.6: Importing data from Illumina systems.
The file formats accepted are:
- Fastq
- Scarf
- Qseq
Note that there is information inside qseq and fastq files specifying whether a read has passed a quality filter or not. If you check Remove failed reads these reads will be ignored during import. For qseq files there is a flag at the end of each read with values 0 (failed) or 1 (passed). In this example, the read is marked as failed and if Remove failed reads is checked, the read is removed.
M10 68 1 1 28680 29475 0 1 CATGGCCGTACAGGAAACACACATCATAGCATCACACGA BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB 0
For fastq files, part of the header information for the quality score has a flag where Y means failed and N means passed. In this example, the read has not passed the quality filter:
@EAS139:136:FC706VJ:2:2104:15343:197393 1:Y:18:ATCACG
Note! In the Illumina pipeline 1.5-1.7, the letter B in the quality score has a special meaning. 'B' is used as a trim clipping. This means that when selecting Illumina pipeline 1.5-1.7, the reads are automatically trimmed when a B is encountered in the input file. This will happen also if you choose to discard quality scores during import.
If you import paired data and one read in a pair is removed during import, the remaining mate will be saved in a separate sequence list with single reads.
For all formats, compressed data in gzip format is also supported (.gz).
The General options to the left are:
- Paired reads. For paired import, you can select whether the data is Paired-end or Mate-pair. For paired data, the Workbench expects the first reads of the pairs to be in one file and the second reads of the pairs to be in another. When importing one pair of files, the first file in a pair will is assumed to contain the first reads of the pair, and the second file is assumed to contain the second read in a pair. So, for example, if you had specified that the pairs were in forward-reverse orientation, then the first file would be assumed to contain the forward reads. The second file would be assumed to contain the reverse reads.
When loading files containing paired data, the CLC Cancer Research Workbench sorts the files selected according to rules based on the file naming scheme:
- For files coming off the CASAVA1.8 pipeline, we organize pairs according to their identifier and chunk number. Files named with
_R1_are assumed to contain the first sequences of the pairs, and those with_R2_in the name are assumed to contain the second sequence of the pairs. - For other files, we sort them all alphanumerically, and then group them two by two. This means that files 1 and 2 in the list are loaded as pairs, files 3 and 4 in the list are seen as pairs, and so on.
In the simplest case, the files are typically named as shown in figure 6.6. In this case, the data is paired end, and the file containing the forward reads is called
s_1_1_sequence.txtand the file containing reverse reads is calleds_1_2_sequence.txt. Other common filenames for paired data, like_1_sequence.txt,_1_qseq.txt,_2_sequence.txtor_2_qseq.txtwill be sorted alphanumerically. In such cases, files containing the final_1should contain the first reads of a pair, and those containing the final_2should contain the second reads of a pair.For files from CASAVA1.8, files with base names like these: ID_R1_001, ID_R1_002, ID_R2_001, ID_R2_002 would be sorted in this order:
- ID_R1_001
- ID_R2_001
- ID_R1_002
- ID_R2_002
The data in files ID_R1_001 and ID_R2_001 would be loaded as a pair, and ID_R1_002, ID_R2_002 would be loaded as a pair.
Within each file, the first read of a pair will have a
1somewhere in the information line. In most cases, this will be a/1at the end of the read name. In some cases though (e.g. CASAVA1.8), there will be a1elsewhere in the information line for each sequence. Similarly, the second read of a pair will have a2somewhere in the information line - either a/2at the end of the read name, or a2elsewhere in the information line.If you do not choose to discard your read names on import (see next parameter setting), you can quickly check that your paired data has imported in the pairs you expect by looking at the first few sequence names in your imported paired data object. The first two sequences should have the same name, except for a
1or a2somewhere in the read name line.Paired-end and mate-pair data are handled the same way with regards to sorting on filenames. Their data structure is the same the same once imported into the Workbench. The only difference is that the expected orientation of the reads: reverse-forward in the case of mate pairs, and forward-reverse in the case of paired end data. Read more about handling paired data.
- For files coming off the CASAVA1.8 pipeline, we organize pairs according to their identifier and chunk number. Files named with
- Discard read names. For high-throughput sequencing data, the naming of the individual reads is often irrelevant given the huge amount of reads. This option allows you to discard read names to save disk space.
- Discard quality scores. Quality scores are visualized in the mapping view and they are used for SNP detection. If this is not relevant for your work, you can choose to Discard quality scores. One of the benefits from discarding quality scores is that you will gain a lot in terms of reduced disk space usage and memory consumption. Read more about the quality scores of Illumina below.
- MiSeq de-multiplexing. For MiSeq multiplexed data, one file includes all the reads containing barcodes/indices from the different samples (in case of paired data it will be two files). Using this option, the data can be divided into groups based on the barcode/index. This is typically the desired behavior, because subsequent analysis can then be executed in batch on all the samples and results can be compared at the end. This is not possible if all samples are in the same file after import. The reads are connected to a group using the last number in the read identifier.
- Trim reads. This option applies to Illumina Pipeline 1.5 to 1.7. In this pipeline, the value 2 (B) has special meaning and is used as a trim clipping. This means that when selecting Illumina Pipeline 1.5 and later, the reads are trimmed when a B is encountered in the input file if the Trim reads option is checked.
Click Next to adjust how to handle the results. We recommend choosing Save in order to save the results directly to a folder, since you probably want to save anyway before proceeding with your analysis. There is an option to put the import data into a separate folder. This can be handy for better organizing subsequent analysis results and for batch processing.
Subsections