Bubble resolution
Before the graph structure is converted to contig sequences, bubbles are resolved. As mentioned previously, a bubble is defined as a bifurcation in the graph where a path furcates into two nodes and then merge back into one. An example is shown in figure 27.14.

Figure 27.14: A bubble caused by a heteroygous SNP or a sequencing error.
In this simple case the assembler will collapse the bubble and use the route through the graph that has the highest coverage of reads. For a diploid genome with a heterozygous variant, there will be a fifty-fifty distribution of reads on the two variants, and this means that the choice of one allele over the other will be arbitrary. If heterozygous variants are important, they can be identified after the assembly by mapping the reads back to the contig sequences and performing standard variant calling. For random sequencing errors, it is more straightforward; given a reasonable level of coverage, the erroneous variant will be suppressed.
Figure 27.15 shows an example of a data set where the reads have systematic errors. Some reads include five As and others have six. This is a typical example of the homopolymer errors seen with the 454 and Ion Torrent platforms.

Figure 27.15: Reads with systematic errors.
When these reads are assembled, this site will give rise to a bubble in the graph. This is not a problem in itself, but if there are several of these sites close together, the two paths in the graph will not be able to merge between each site. This happens when the distance between the sites is smaller than the word size used (see figure 27.16).
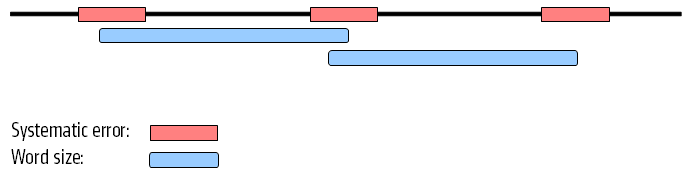
Figure 27.16: Several sites of errors that are close together compared to the word size.
In this case, the bubble will be very large because there are no complete words in the regions between the homopolymer sites, and the graph will look like figure 27.17.

Figure 27.17: The bubble in the graph gets very large.
If the bubble is too large, the assembler will have to break it into several separate contigs instead of producing one single contig.
The maximum size of bubbles that the assembler should try to resolve can be set by the user. In the case from figure 27.17, a bubble size spanning the three error sites will mean that the bubble will be resolved (see figure 27.18).
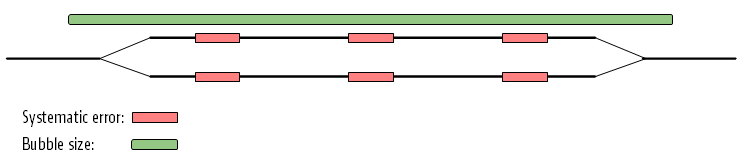
Figure 27.18: The bubble size needs to be set high enough to encompass the three sites.
While the default bubble size is often fine when working with short, high quality reads, considering the bubble size can be especially important for reads generated by sequencing platforms yielding long reads with either systematic errors or a high error rate. In such cases, a higher bubble size is recommended. For example, as a starting point, one could try half the length of the average read in the data set and then experiment with increasing and decreasing the bubble size in small steps. For data sets with a high error rate it is often necessary to increase the bubble size to the maximum read length or more. Please keep in mind that increasing the bubble size also increases the chance of misassemblies.