Annotate Variants (WGS)
The Annotate Variants (WGS) template workflow can add the following annotation types to a variant track, annotation track, expression track or statistical comparison track:
- Gene names Adds names of genes whenever a variant is found within a known gene.
- mRNA Adds names of mRNA whenever a variant is found within a known transcript.
- CDS Adds names of CDS whenever a variant is found within a coding sequence.
- Amino acid changes Adds information about amino acid changes caused by the variants.
- Information from ClinVar Adds information about the relationships between human variations and their clinical significance.
- Information from dbSNP Common Adds information from the "Single Nucleotide Polymorphism Database", which is a general catalog of genome variation, including SNPs, multinucleotide polymorphisms (MNPs), insertions and deletions (indels), and short tandem repeats (STRs).
- PhastCons Conservation scores The conservation scores, in this case generated from a multiple alignment with a number of vertebrates, describe the level of nucleotide conservation in the region around each variant.
Run the Annotate Variants (WGS) workflow
- To run the Annotate Variants (WGS) template workflow, go to:
Workflows | Template Workflows | Biomedical Workflows (
 ) | Whole Genome Sequencing (
) | Whole Genome Sequencing ( ) | General Workflows (WGS) (
) | General Workflows (WGS) ( ) | Annotate Variants (WGS) (
) | Annotate Variants (WGS) ( )
)
- In the first wizard step, select the input variant track, annotation track, expression track or statistical comparison track to annotate (figure 17.1).
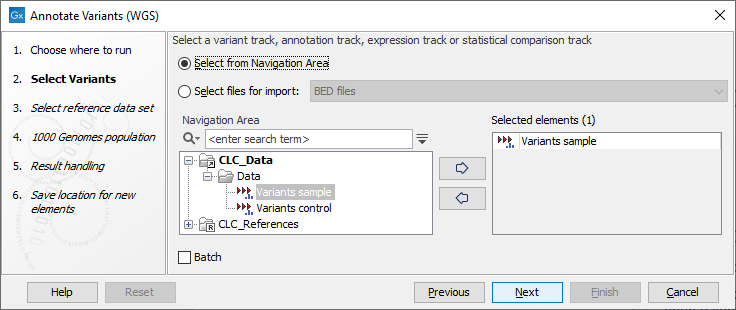
Figure 17.1: Select the relevant track to annotate. - In the next dialog, you have to select which data set should be used to annotate variants (figure 17.2).
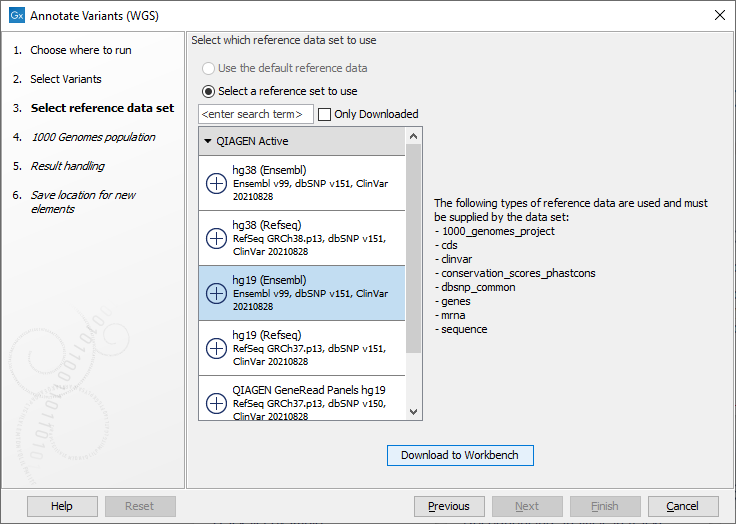
Figure 17.2: Choose the relevant reference Data Set to annotate. - The 1000 Genomes population(s) is bundled in the downloaded reference dataset and therefore preselected in this step. If you want to use another variant track you can browse in the navigation area for the preferred track to use (figure 17.3).
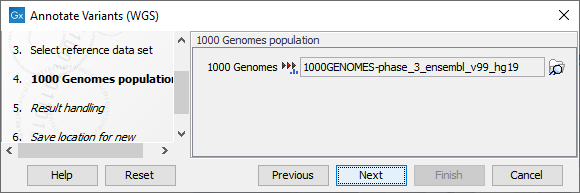
Figure 17.3: Use the preselected 1000 Genomes population(s) or select another variant track. - In the last wizard step you can check the selected settings by clicking on the button labeled Preview All Parameters.
In the Preview All Parameters wizard you can only check the settings, and if you wish to make changes you have to use the Previous button from the wizard to edit parameters in the relevant windows.
- Choose to Save your results and click on the button labeled Finish.
Output from the Annotate Variants (WGS) workflow
The outputs generated are:
- Filtered Annotated Variant Track Hold the mouse over one of the variants or right-clicking on the variant. A tooltip will appear with detailed information about the variant.
- An Amino Acid Track Shows the consequences of the variants at the amino acid level in the context of the original amino acid sequence. A variant introducing a stop mutation is illustrated with a red amino acid.
- Track List Annotated Variants A collection of tracks presented together. Shows the annotated variant track together with the human reference sequence, genes, transcripts, coding regions, and variants detected in dbSNP Common, ClinVar, 1000 Genomes, and PhastCons conservation scores (see figure 17.4).
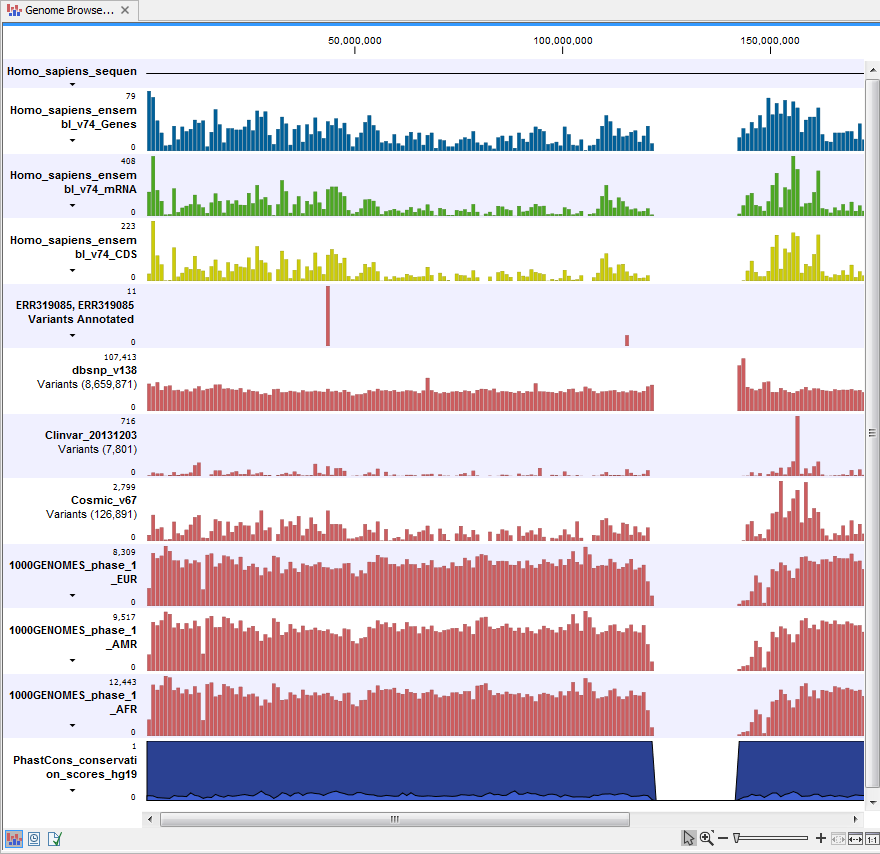
Figure 17.4: The output from the Annotate Variants template workflow is a track list containing individual tracks for all added annotations.
It is possible to add tracks to the Track List by dragging the track directly from the Navigation Area to the Track List view. On the other hand, if you delete the annotated variant track, this track will also disappear from the Track List.
Open the annotated track as a table (see figure 17.5). The table and the Track List are linked; if you click on an entry in the table, this particular position in the genome will automatically be brought into focus in the Track List view.
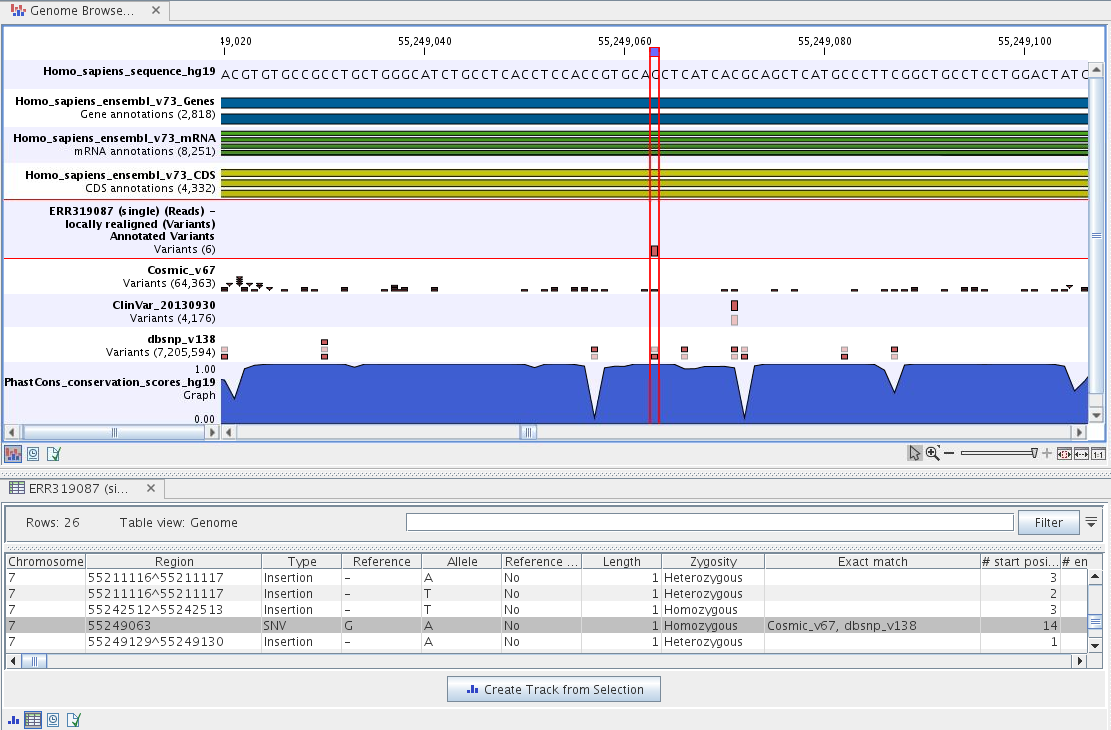
Figure 17.5: The output from the Annotate Variants template workflow is a track list linked with the variant table view.
You may be met with a warning as shown in figure 17.6. This is simply a warning telling you that it may take some time to create the table if you are working with tracks containing large amounts of annotations. Please note that in case none of the variants are present in ClinVar or dbSNP Common, the corresponding annotation column headers are missing from the result.
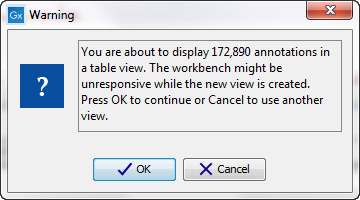
Figure 17.6: Warning that appears when you work with tracks containing many annotations.
Adding information from other sources may help you identify interesting candidate variants for further research. For example, common genetic variants (present in the HapMap database) or variants known to play a role in drug response or other relevant phenotypes (present in the ClinVar database) can easily be identified. Furthermore, variants not found in the ClinVar database can be prioritized based on amino acid changes in case the variant causes changes on the amino acid level.
A high conservation level between different vertebrates or mammals in the region containing the variant can also be used to give a hint about whether a given variant is found in a region with an important functional role. If you would like to use the conservation scores to identify interesting variants, we recommend that variants with a conservation score of more than 0.9 (PhastCons score) are prioritized over variants with lower conservation scores.
It is possible to filter variants based on their annotations. This type of filtering can be facilitated using the table filter found at the top part of the table. If you are performing multiple experiments where you would like to use the exact same filter criteria, you can include in a workflow the Filter on Custom Criteria tool configured with the desired set of criteria.