Detect and Refine Fusion Genes
Detect and Refine Fusion Genes identifies candidate fusion genes using information from unaligned ends of reads in a mapping generated by RNA-Seq Analysis. Candidate fusion genes are then evaluated by mapping a full set of reads back to a reference set containing the original gene sequences and the candidate fusion gene sequences. Statistical scores, reports and other outputs are generated, allowing detailed consideration of the evidence for fusion genes in the data set.
Identifying fusion genes is a two-step process.
- The detect step: Potential fusions are identified by re-mapping to the reference the unaligned ends of reads in the mapping. Reads that have an unaligned end close to an exon boundary that can be remapped close to another exon boundary are consistent with a fusion event. Reads with unaligned ends that map far from an exon boundary can also be considered by enabling the option "Detect fusions with novel exon boundaries".
- The refine step: The evidence for each detected fusion is evaluated. Sequences representing potential fusion genes are created (figure 31.51), and all reads are mapped in an RNA-Seq mapping against the original reference sequences plus the potential fusion gene sequences. The number of reads supporting each fusion gene are counted, and the number of reads supporting the genes from the original RNA-Seq Analysis are counted. Z-scores and p-values for the fusion genes are then calculated using a binomial test.
See RNA-Seq Analysis for information about RNA-Seq mappings.
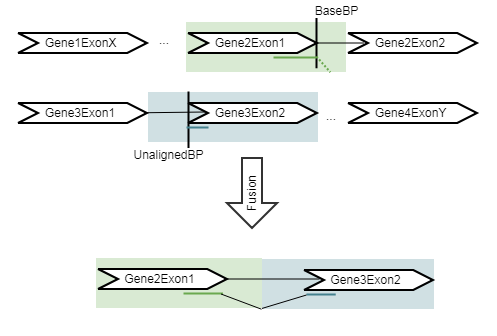
Figure 31.54: An artificial chromosome is created consisting of the vicinity of both ends of the fusion.
The Detect and Refine Fusion Genes tool can be found in the Toolbox at:
Toolbox | RNA-Seq and Small RNA Analysis (![]() )| RNA-Seq Tools (
)| RNA-Seq Tools (![]() ) | Detect and Refine Fusion Genes (
) | Detect and Refine Fusion Genes (![]() )
)
The tool takes as input one or more sequence lists (![]() ). The following references are required (figure 31.52):
). The following references are required (figure 31.52):
- Reads track: A read mapping (
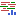 ) produced by RNA-Seq Analysis, where the same sequence lists used as input here were used for the RNA-Seq Analysis.
) produced by RNA-Seq Analysis, where the same sequence lists used as input here were used for the RNA-Seq Analysis.
- Reference sequence, mRNA and Gene tracks containing the genome annotated with transcripts and genes. The same tracks as used for RNA-Seq Analysis should be provided.
Optionally, a CDS and Primer tracks can be provided to obtain information about CDS and primers for the identified fusion genes, see Output from the Detect and Refine Fusion Genes tool.
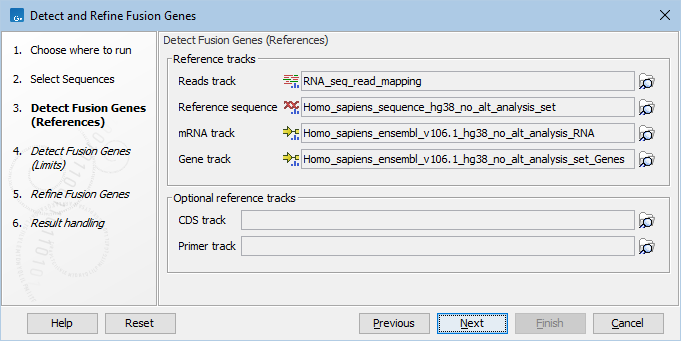
Figure 31.55: Reference tracks for Detect and Refine Fusion Genes.
The following options can be adjusted (figures 31.53 and 31.54):
Figure 31.56: Default parameters for detecting fusion genes.
Figure 31.57: Default parameters for refining fusion genes.
- Maximum number of fusions: The maximum number of putative fusions that will be evaluated. Multiple different possible fusion breakpoints between the same two genes count as 1 fusion.
- Minimum unaligned end read count: Fusions supported by fewer unaligned ends than specified will not be considered in the refine step.
- Minimum length of unaligned sequence: Only unaligned ends longer than this will be used for detecting fusions.
- Maximum distance to known exon boundary: Reads with unaligned ends must map within this distance of a known exon boundary, and unaligned ends must map within this distance of another known exon boundary, to be recorded as supporting a fusion event.
Increasing this parameter counts reads that are further from a known exon boundary as if they fused at the boundary, which increases the signal for the fusion. However, increasing the parameter also decreases the resolution at which a fusion can be detected: for example, if "maximum distance to known exon boundary = 10" then two transcripts with exon boundaries 9nt apart will not be distinguished, and the tool will only produce artificial fusion transcripts for one of them, which can reduce the number of mapping reads in the refine step.
- Maximum distance for broken pairs fusions: The algorithm uses broken pairs to find additional support for fusion events. If a pair of reads originally mapped as a broken pair, but would not be considered broken if mapped across the fusion breakpoints (because the two reads in the pair then get close enough to each other), then that pair of reads supports the fusion event as "fusion spanning reads". The "Maximum distance for broken pairs fusions" parameter specifies how close to each other two broken pairs must map across the fusion breakpoints in order for them to be considered fusion spanning reads. This is usually set to the maximum paired end distance used for the Illumina import of reads.
- Assumed error rate: Value used to calculate Z-score and p-value.
- Promiscuity threshold: Only up to this number of fusion partners will be reported for a given gene.
This parameter does not limit the number of fusion breakpoints that can be reported between two genes, which is capped at 20 pairs of breakpoints:
We limit the number of breakpoint pairs between the same two genes by selecting the highest possible p-value threshold that admits at most 20 breakpoint pairs.
- Detect exon skippings: When enabled, same-gene fusions are reported.
- Detect with novel exon boundaries: When enabled, fusions beyond the distance set for "Maximum distance to known exon boundary" are additionally reported where breakpoints are not at canonical exon boundaries.
- Allow fusions with novel exon boundaries in both genes: When enabled, fusions with novel exon boundaries in both genes are reported. If not enabled, fusions with just one novel breakpoint are reported. This option is only relevant when Detect with novel exon boundaries is enabled. By default, this parameter is not enabled, to reduce the number of false positive fusions. Enabling it is useful for exhaustive searches of novel fusions.
- Only use fusion primer reads: When enabled, the input sequence list is filtered to retain reads that are annotated as originating from a primer that is designed for fusion calling. This option requires that reads are annotated with by the Biomedical Genomics Analysis tool Extract Reads Matching Primers
(see http://resources.qiagenbioinformatics.com/manuals/biomedicalgenomicsanalysis/current/index.php?manual=Extract_Reads_Matching_Primers.html).
- Minimum number of supporting reads: Fusions supported by fewer reads than specified will have "Few supporting reads" in the Filter column of the fusion track output.
- Maximum p-value: Fusions with a p-value higher than this value will have "High p-value" in the Filter column of the fusion track output.
- Minimum Z-score: Fusions with a Z-score lower than this value will have "Low Z-score" in the Filter column of the fusion track output.
- Breakpoint distance: The minimum distance from one end of a read to the breakpoint, or in other words the minimum number of nucleotides that a read must cover on each side of the breakpoint, for it to be counted as a fusion supporting read. If you set this value to 10, reads which only covers 9 bases on one side of the breakpoint will not count as fusion evidence.
- Skip nonsignificant breakpoints (report): When enabled, nonsignificant breakpoints are not added to the report.
- The Mapping settings are used when mapping the reads to the artificial references. See Mapping settings for details.
Subsections