Expression Analysis from Matrix
The workflow Expression Analysis from Matrix takes one or more Expression Matrix (- a single, multi-sample, normalized Expression Matrix (
 ) / (
) / ( );
);
- a Dimensionality Reduction Plot (
 ) associated with the automated clusters, predicted cell types and additional cell annotations;
) associated with the automated clusters, predicted cell types and additional cell annotations;
- a Heat Map (
 ), a Dot Plot (
), a Dot Plot ( ), and a Violin Plot (
), and a Violin Plot ( ) with the predicted cell types as cell groups;
) with the predicted cell types as cell groups;
- a Cell Abundance Heat Map () with the automated clusters and predicted cell types as cell groups.
- If velocity analysis is run:
- a Phase Portrait Plot (
 ) with per gene information on the velocity dynamics;
) with per gene information on the velocity dynamics;
- a Velocity Genes Scores (
 ) element allowing identification of velocity genes driving the dynamics.
) element allowing identification of velocity genes driving the dynamics.
- a Phase Portrait Plot (
The workflow can be found here:
Template Workflows | Single Cell Workflows (![]() ) | From Imported Data (
) | From Imported Data (![]() ) | Expression Analysis from Matrix (
) | Expression Analysis from Matrix (![]() )
)
If you are connected to a CLC Server via the CLC Single Cell Analysis Module, you will be asked where you would like to run the analysis. We recommend that you run the analysis on a CLC Server when possible.
Using a Fork element, the workflow offers the option to run velocity analysis. To enable this, set Velocity Analysis to Run in the Specify Workflow Path wizard step. See https://resources.qiagenbioinformatics.com/manuals/clcgenomicsworkbench/current/index.php?manual=Fork.html for details.
Choose either one or more Expression Matrix (![]() ) / (
) / (![]() ) or Select files for on-the-fly import and select the format that is compatible with the selected inputs.
Read more about import options in On-the-fly import in workflows.
) or Select files for on-the-fly import and select the format that is compatible with the selected inputs.
Read more about import options in On-the-fly import in workflows.
The workflow offers a number of options. Note that not all parameters can be configured. Open parameters indicate places where customization may be necessary for different samples, but default settings are suitable in most cases.
The workflow can be run using Single Cell hg38 (Ensembl) or Single Cell Mouse (Ensembl) reference data sets (see Reference data management).
|
Note: Reference data elements cannot be configured during workflow execution. If other elements than those provided in the default reference data sets are needed, a custom reference data set can be used, see
https://resources.qiagenbioinformatics.com/manuals/clcgenomicsworkbench/current/index.php?manual=Reference_Data_Sets_defining_Custom_Sets.html.
When creating custom reference data sets, the chosen gene track needs to match the gene annotations used for training the provided Cell Type Classifier ( |
The workflow allows the analysis of multiple samples and you can specify metadata during workflow execution. This is converted to cell annotations and can be used for coloring the cells in the Dimensionality Reduction Plot. However, the workflow expects each sample to be present in just one Expression Matrix, and attempting to define batch units containing more than one Expression Matrix will lead to a failure during execution.
For more details on configuring workflow execution with metadata, see https://resources.qiagenbioinformatics.com/manuals/clcgenomicsworkbench/current/index.php?manual=Running_workflows_in_batch_mode.html. Make sure to inspect the batch overview to check that the analysis will be performed correctly.
For quality control a number of options exist. The option to remove empty droplets is not suitable for protocols that do not use droplets, and removing barcodes with low number of reads or expressed features might be more appropriate. Quality Control (QC) uses the number of reads mapped to the mitochondria, and for this the name of the mitochondria chromosome needs to be provided. The default value is often the correct name. After quality control, the matrices are collected and normalized jointly. Note that batch correction is not performed. Read more about QC and normalization in Gene Expression Matrix.
For clustering and creation of the Dimensionality Reduction Plot plot, it is possible to restrict analysis to highly variable genes. The data is then projected to a lower dimensional space using PCA. You can read about this feature in Feature selection and dimensionality reduction.
The high confidence predicted cell types ("Cell type (high confidence)") are used to group the cells in the expression plots (Heat Map and Dot Plot) and Cell Abundance Heat Map, as well as for scoring the velocity genes. The Cell Abundance Heat Map additionally groups the cells based on the automated clusters obtained with resolution 1.0 ("Leiden (resolution=1.0)"). Any of these groups can be changed to:
- all predicted cell types ("Cell type (all)");
- automated clusters obtained with a different resolution
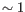 ("Leiden (resolution=)"). All resolutions
("Leiden (resolution=)"). All resolutions
 are produced, in steps of
are produced, in steps of 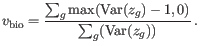 .
.
Subsections