Doublets filter
Certain single-cell protocols can assign the same barcode to two or more cells. For example, in droplet-based data, each droplet has a unique barcode, but droplets can contain more than one cell. For data obtained using combinatorial barcoding, there is a chance that two cells will travel together through all barcoding rounds, creating a doublet.
In this dialog of QC for Single Cell, the Doublets filter can be enabled and customized to remove the barcodes that are detected as being assigned to two cells. This filter should be skipped for single-cell protocols that do not generate doublets.
Note that QC for Single Cell cannot remove barcodes that are assigned to more than two cells. However, these are expected to be present at negligible rates.
There are two types of doublets:
- homotypic doublets are formed by two cells with similar expression profiles;
- heterotypic doublets are formed by two cells with different expression profiles.
Doublet-removal software, which relies on gene expression to detect doublets, cannot identify homotypic doublets, as their expression profiles are indistinguishable from those of other cells. Alternative approaches are required to detect homotypic doublets, such as cell hashing [Stoeckius et al., 2018] and SNPs in multiplexed samples [Kang et al., 2018].
The Doublets filter simulates heterotypic doublets by averaging the expression of two random barcodes that are sufficiently different from each other. These artifical doublets are then used for predicting which of the input barcodes are doublets.
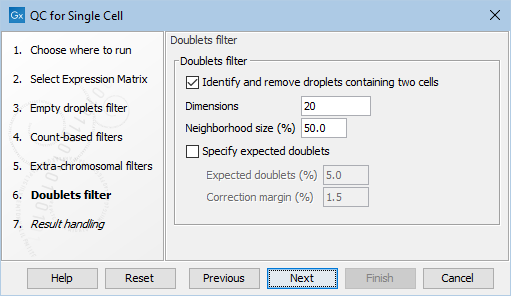
Figure 7.8: The default settings in the Doublets filter dialog.
The following options can be adjusted in the Doublets filter dialog (figure 7.8):
- Identify and remove barcodes assigned to two cells. Enables filtering of the doublets. This should be unchecked for single-cell protocols that do not generate doublets.
- Dimensions. The number of PC dimensions to be used when reducing the dimensions of the expression data.
- Neighborhood size (%). Simulated doublets are obtained from barcodes that are not in each other's neighborhood. The size of the neighborhood is specified as % of input barcodes. Note that this is relative to the number of barcodes that pass all previous filters of QC for Single Cell. The optimal neighborhood size is data-set specific and would typically depend on the number of clusters in the data.
- Platform. The percentage of barcodes that are expected to be doublets depends on the platform used for generating the single-cell data. Choosing the platform sets the default values for Expected doublets (%) and Correction margin (%), even though Specify expected doublets is not checked (see below). The following options are available:
- 10x Geonomics. Expected doublets (%) is set to 1% per 1000 captured cells, and Correction margin (%) is set to half of this.
- Parse Biosciences. Expected doublets (%) is set differently according to the kit size:
- 3% for at most 10,000 captured cells,
- 5% for at most 100,000 captured cells,
- 7% otherwise.
- Other. No default values are used. It is recommended to specify the expected doublets by checking Specify expected doublets.
- Specify expected doublets. Check this option to specify approximately how many doublets are present in the data. This option should be used whenever a reasonable expectation is known, as it is very important for an accurate detection of doublets.
- Expected doublets (%). The percentage of barcodes that are expected to be doublets, relative to the number of captured cells.
- Correction margin (%). The percentage of predicted doublets will lie in the interval given by `Expected doublets (%)'
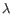 `Correction margin (%)'.
`Correction margin (%)'.
|
Note: Expected doublets (%) is relative to the number of captured cells, with estimates dependent on the platform:
The Doublets filter receives as input only the high quality cells that pass all filters. |
For more details on how doublets are detected, see Doublet calling.