HDF5 formats
AnnData, Cell Ranger HDF5, h5Seurat and Loom are HDF5 formats, with specific requirements regarding structure of the data. An HDF5 file is organized in a hierarchical structure with:
- groups, containing zero or more groups or datasets;
- datasets: multidimensional arrays of data elements.
Metadata for groups and datasets is stored in associated attribute lists. Groups and datasets can often be themselves semantically interpreted as attributes.
The HDF5 file
All HDF5 importers contain an Expression matrix option, used for specifying the HDF5 file to be imported.
The AnnData, h5Seurat and Loom importers can be customized to import different attributes from the file. These attributes can be previewed by clicking the `Preview' button.
The preview (figure 4.7) shows the available attributes in a table. One column corresponds to one attribute, for either features or cells, as selected in the menu to the left.
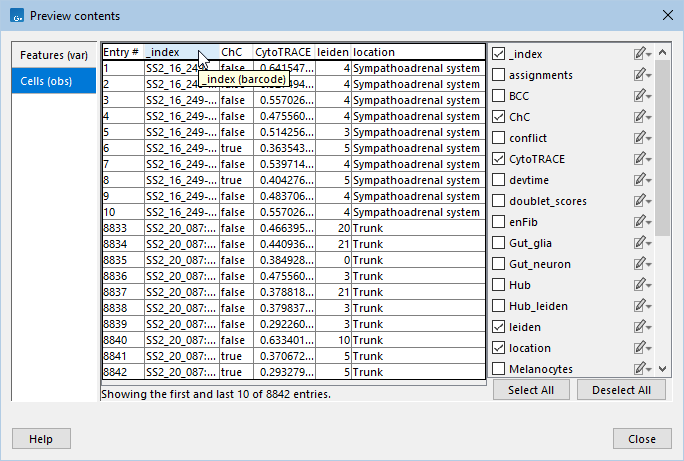
Figure 4.7: Previewing cell attributes found under the `obs' group for the GSE201257 AnnData expression matrix from the Gene Expression Omnibus repository. The `_index' attribute defines the barcode, as shown in the tooltip.
Hovering the cursor over a column name, either at the top of the table or on the menu to the right, displays a tooltip with the type of data stored in the attribute (for example, boolean or integer) and if the attribute is always used by the importer (for example, for the barcode or the sample).
Right-clicking on the column name at the top of the table, or clicking on the edit icon (![]() ), displays a menu from which the attribute can be added to or removed from relevant wizard options (figure 4.8).
), displays a menu from which the attribute can be added to or removed from relevant wizard options (figure 4.8).
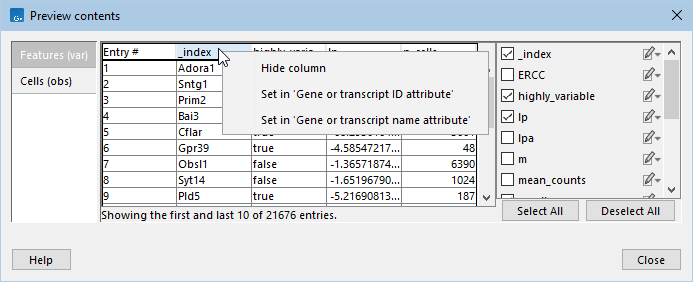
Figure 4.8: Previewing feature attributes found under the `var' group for the GSE201257 AnnData expression matrix from the Gene Expression Omnibus repository. Right-clicking on the `_index' column name displays a menu.
AnnData importer
The expression matrix in an AnnData (h5ad) is in a sparse dataset `X', while features and cells are described using the `var' and `obs' groups, respectively. See https://anndata.readthedocs.io/ for more details.
The `_index' attribute on group `obs' defines the cell identification, and the interpretation of this is specified by the Cell format.
- Gene or transcript ID attribute (Optional). A `var' attribute describing an identifier for a gene or transcript (e.g., ENSG00000243485 for ENSEMBL).
- Gene or transcript name attribute (Optional). A `var' attribute describing the name for a gene or transcript. If left empty, the `_index' attribute on group `var' is used.
h5Seurat importer
A h5seurat file may contain multiple assays and each assay may contain multiple expression matrices, e.g., counts and normalized expressions. The matrices can be sparse or dense. See https://mojaveazure.github.io/seurat-disk/articles/h5Seurat-spec.html for more details.
Only one assay and matrix can be imported at a time. The h5Seurat importer expects the format version 4.0.0.
The `cell.names' attribute contains the cell identification, and the interpretation of this is specified by the Cell format. If the sample is not set through Cell format or Sample, the sample for each cell is read from the `orig.ident' attribute on group `meta.data'.
The gene or transcript names are read from the `features' attribute of the selected assay.
- Assay (Optional). The name of the assay to import. If left empty, the assay in the `active.assay' attribute will be used.
- Import expressions from (Optional). The matrix for the selected assay to import. The matrix may be sparse (e.g., `counts' or `data') or dense (e.g., `scale.data'). If left empty, the importer will use `counts'.
Loom importer
A Loom file has an internal structure consisting of a main matrix, optional `layers' of the same size as the main matrix and row and column attributes (describing features and cells, respectively). See https://linnarssonlab.org/loompy/format/index.html for details on the format.
The Loom importer expects the Loom format version 3.0.0.
- Spliced layer. The layer where the spliced counts are stored.
- Unspliced layer. The layer where the unspliced counts are stored.
- Cell ID attribute (Optional). A column attribute identifying the cell by its barcode and sample. The interpretation of this value is specified by the Cell format.
- Gene or transcript ID attribute (Optional). A row attribute describing an identifier for a gene or transcript (e.g., ENSG00000243485 for ENSEMBL).
- Gene or transcript name attribute. A row attribute describing the name for a gene or transcript. If no names are present, then it is also possible to set this to the same value as the Gene or transcript ID attribute.