Filter against known variants
Comparison with known variants from variant databases is a key concept when working with
resequencing data. The CLC Genomics Workbench provides two tools for facilitating this
task: one for annotating your experimental variants with information from
known variants (e.g. adding information about phenotypes like cancer
associated with a certain variant allele), and one for filtering your
experimental variants based on this information (e.g. for removing common
variants). The first tool is explained in Annotating known variants, while this section explains the latter.
Any variant track can be used as the "known variants track". It may either be produced by the CLC Genomics Workbench, imported or downloaded from variant database resources like dbSNP, 1000 genomes, HapMap etc. (see Import tracks from file and Download reference genome).
This section will use the filter tool as an example, since the core of the tools are the same:
Toolbox | Resequencing (![]() ) | Annotate and Filter Variants | Filter against Known Variants
) | Annotate and Filter Variants | Filter against Known Variants
This opens a dialog where you can select a variant track (![]() ) with experimental data that should be filtered.
) with experimental data that should be filtered.
Clicking Next will display the dialog shown in figure 25.50
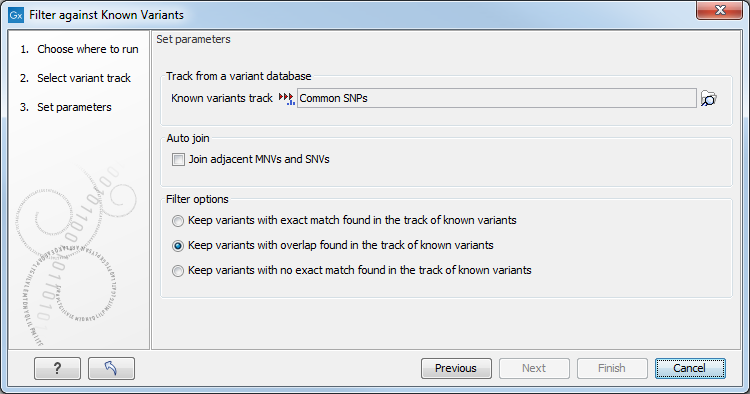
Figure 25.50: Specifying a variant track to filter against.
Select (![]() ) one or more tracks of known variants to compare against. The tool will then compare
each of the variants provided in the input track with the variants in the track of known variants. There are three modes of filtering:
) one or more tracks of known variants to compare against. The tool will then compare
each of the variants provided in the input track with the variants in the track of known variants. There are three modes of filtering:
- Keep variants with exact match found in the track of known variants
- This will filter away all variants that are not found in the track of known variants. This mode can be useful for filtering against tracks with known disease-causing mutations, where the result will only include the variants that match the known mutations. The criteria for matching are simple: the variant position and allele both have to be identical in the input and the known variants track (however, note the extra option for joining adjacent SNVs and MNVs described below). For each variant found, the result track will include information from the known variant. Please note that the exact match criterion can be too stringent, since the database variants need to be reported in the exact same way as in the sample. Some databases report adjacent indels and SNVs separately, even if they would be called as one replacement using the variant detection of CLC Genomics Workbench. In this case, we recommend using the overlap option instead and manually interpret the variants found.
- Keep variants with overlap found in the track of known variants
- The first mode is based on exact matching of the variants. This means that if the allele is reported differently in the set of known variants, it will not be identified as a known variant. This is typically not the case with isolated SNVs, but for more complex variants it can be a problem. Instead of requiring a strict match, this mode will keep variants that overlap with a variant in the set of known variants. The result will therefore also include all variants that have an exact match in the track of known variants. This is thus a more conservative approach and will allow you to inspect the annotations on the variants instead of removing them when they do not match. For each variant, the result track will include information about overlapping or strictly matched variants to allow for more detailed exploration.
- Keep variants with no exact match found in the track of known variants
- This mode can be used for filtering away common variants if they are not of interest. For example, you can download a variant track from 1000 genomes or dbSNP and use that for filtering away common variants. This mode is based on exact match.
Since many databases do not report a succession of SNVs as one MNV, it is not possible to directly compare variants called with CLC Genomics Workbench with these databases. In order to support filtering against these databases anyway, the option to Join adjacent SNVs and MNVs can be enabled. This means that an MNV in the experimental data will get an exact match, if a set of SNVs and MNVs in the database can be combined to provide the same allele.
Note! This assumes that SNVs and MNVs in the track of known variants represent the same allele, although there is no evidence for this in the track of known variants.