Expression settings
When the reference has been defined, click Next and you are presented with the dialog shown in figure 31.8.
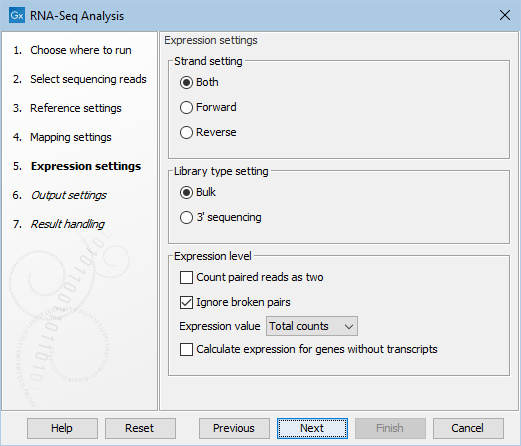
Figure 31.8: Defining how expression values should be calculated.
These parameters determine the way expression values are counted.
Strand setting
- Both. Reads are mapped both in the same and reversed orientation as the transcript from which they originate. This is the default.
- Forward. Reads are mapped in the same orientation as the transcript from which they originate.
- Reversed. Reads are mapped in the reverse orientation as the transcript from which they originate.
If a strand specific protocol for read generation has been used, the user should choose the corresponding setting. This allows assignment of the reads to the right gene in cases where overlapping genes are located on different strands. Without the strand-specific protocol, this would not be possible (see [Parkhomchuk et al., 2009]). Note that when not running RNA-Seq with 'Both', only pairs in forward-reverse orientation are used, meaning that mate pairs are not supported.
Library type setting
- Bulk. Reads are expected to be uniformly distributed across the full length of transcript. This is the default.
- 3' sequencing. Reads are expected to be biased towards the 3' end of transcripts. Then:
- Report quality control is tailored for low input 3' sequencing applications.
- No TE tracks are produced because the EM algorithm requirement for uniform coverage along transcript bodies is not fulfilled.
- TPM (Transcripts per million) is calculated as (exon reads in gene) / (total exon reads) x 1 million. This is because, in the absence of fragmentation, each read corresponds to a sequenced transcript.
- RPKM is set equal to TPM, which preserves the expected property that RPKM is proportional to TPM. This is because the standard definition of RPKM normalizes by the length of the transcript that generates each read, and it is often not possible to uniquely identify a transcript based on the 3' end.
- When analyzing reads that have been annotated with UMIs by tools of the Biomedical Genomics Analysis plugin:
- Expression values in the GE track are based on the number of distinct UMIs for each gene, rather than the number of reads.
- Values reported in the "Distribution of biotypes" section of RNA-Seq reports are calculated based on the number of distinct UMIs for each gene. Other values in the report are as described in RNA-Seq report.
Paired reads counting scheme
The CLC Genomics Workbench supports the direct use of paired data for RNA-Seq. A combination of single reads and paired reads can also be used. There are three major advantages of using paired data:
- Since the mapped reads span a larger portion of the reference, there will be fewer non-specifically mapped reads. This means that generally there is a greater accuracy in the expression values.
- This in turn means that there is a greater chance of accurately measuring the expression of transcript splice variants. As single reads (especially from the short reads platforms) typically only span one or two exons, many cases will occur where expression of splice variants sharing the same exons cannot be determined accurately. With paired reads, more combinations of exons will be identified as being unique for a particular splice variant.31.1
- It is possible to detect Gene fusions when one read in a pair maps in one gene and the other part maps in another gene. Several reads exhibiting the same pattern supports the presence of a fusion gene.
You can read more about how paired data are imported and handled in General notes on handling paired data.
When counting the mapped reads to generate expression values, the CLC Genomics Workbench needs to be told how to handle the counting of paired reads that map as
- an intact pair;
- a broken pair, when the reads map outside the estimated pair distance, map in the wrong orientation, or only one of the reads of the pair maps.
Single mapped reads are always given a count of one.
The default behavior of the CLC Genomics Workbench is to count fragments (FPKM) rather than individual reads for intact pairs. That is, an intact pair is given a count of one ('Count paired reads as two' is not checked). Neither member of a broken pair is counted ('Ignore broken pairs' is checked). The reasoning is that when reads map as a broken pair, it is an indication that something is not right. For example, perhaps the transcripts are not represented correctly on the reference or there are errors in the data. In general, more confidence can be placed on an intact pair representing transcription within the sample. If a combination of paired and single reads are input into the analysis, then single reads that map are given a count of one. This is different from reads input into the analysis as part of a pair, but where their partner did not map.
In some situations it may be too strict to disregard broken pairs. This could be the case where there is a high degree of variation in the sample compared to the reference or where the reference lacks comprehensive transcript annotations. By checking 'Count paired reads as two', mapped 'reads' (RPKM) rather than mapped 'fragments' (FPKM) are counted. The two reads in an intact pair are each counted as one mapped read (so an intact pair contributes with a total count of two), and mapped members of broken pairs will each get a count of one ('Ignore broken pairs' is disabled).
For specific protocols generating chimeric reads, it is desirable to count intact pairs as one ('Count paired reads as two' is not checked) and to also count the mapped members of broken pairs ('Ignore broken pairs' is not checked). When choosing this option, it is not possible to detect Gene fusions.
Note that if not using the default behavior, the value does not correctly represent the abundance of fragments being sequenced, since the two reads of a pair derive from the same fragment and can increase the value by two, whereas a fragment sequenced with single reads only give rise to one read and increases the value by one.
Regardless of the chosen option, the value will be given in a column called "RPKM" for all subsequent analysis.
Expression value
Please note that reads that map outside genes are counted as intergenic hits only and thus do not contribute to the expression values. If a read maps equally well to a gene and to an inter-genic region, the read will be placed in the gene.
The expression values are created on two levels as two separate result files: one for genes and one for transcripts (if the "Genome annotated with genes and transcripts" is selected in figure 31.4). The content of the result files is described in RNA-Seq results.
The Expression value parameter describes how expression per gene or transcript can be defined in different ways on both levels:
- Total counts. When the reference is annotated with genes only, this value is the total number of reads mapped to the gene. For un-annotated references, this value is the total number of reads mapped to the reference sequence. For references annotated with transcripts and genes, the value reported for each gene is the number of reads that map to the exons of that gene. The value reported per transcript is the total number of reads mapped to the transcript.
- Unique counts. This is similar to the above, except only reads that are uniquely mapped are counted (read more about the distribution of non-specific matches in Defining mapping options for RNA-Seq).
- TPM. (Transcripts per million). This is computed as
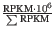 , where the sum is over the RPKM values of all genes/transcripts.
, where the sum is over the RPKM values of all genes/transcripts.
- RPKM. This is a normalized form of the "Total counts" option (see more in Definition of RPKM).
Please note that all values are present in the output. The choice of expression value only affects how Expression Tracks are visualized in the track view but the results will not be affected by this choice as the most appropriate expression value is automatically selected for the analysis being performed: for detection of differential expression this is the "Total counts" value, and for the other tools this is a normalized and transformed version of the "Total counts" as described below.
Calculate expression for genes without transcripts
For genes without annotated transcripts, the RPKM cannot be calculated since the total length of all exons is needed. By checking the Calculate expression for genes without transcripts, the length of the gene will be used in place of an "exon length". If the option is not checked, there will be no RPKM value reported for those genes.
|
Definition of RPKM RPKM, Reads Per Kilobase of exon model per Million mapped reads, is defined in this way [Mortazavi et al., 2008]:
For prokaryotic genes and other non-exon based regions, the calculation is performed in this way:
|
Footnotes
- ... variant.31.1
- Note that the CLC Genomics Workbench only calculates the expression of the transcripts already annotated on the reference.