Import tracks
Tracks (see Tracks) are imported in a special way, because extra information is needed in order to interpret the files correctly.
Tracks are imported using: click Import (![]() ) in the Toolbar | Tracks This will
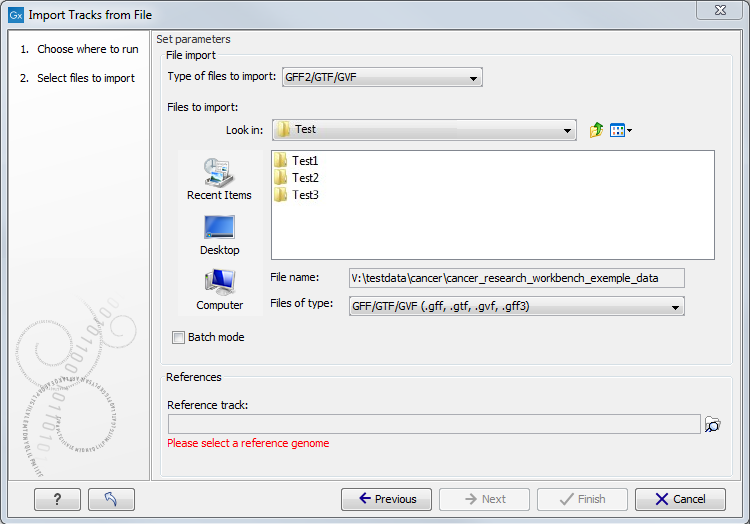
open a dialog as shown in figure 6.2.
) in the Toolbar | Tracks This will
open a dialog as shown in figure 6.2.
Figure
6.2: Select files to import.
At the top, you select the file type to import. Below, select the files to import. If import is performed with the batch option selected, then each file is processed independently and separate tracks are produced for each file. If the batch option is not selected, then variants for all files will be added to the same track (or tracks in the case VCF files including genotype information). The formats currently accepted are:
- FASTA
- This is the standard fasta importer that
will produce a sequence track rather than a standard fasta sequence. Please
note that this could also be achieved by importing using Standard
import and subsequently converting the sequence or
sequence list to a track (see Converting data to tracks and
back).
- GFF2/GTF/GVF
- A GFF2/GTF
file does not contain any sequence information, it only contains a list of
various types of annotations. A GVF file is similar to a GFF file but uses
Sequence Ontology to describe genome variation data (see https://github.com/The-Sequence-Ontology/Specifications/blob/master/gvf.md). For these formats, the importer
adds the annotation in each of the lines in the file to the chosen sequence,
at the position or region in which the file specifies that it should go, and
with the annotation type, name, description etc. as given in the file.
However, special treatment is given to annotations of the types CDS, exon,
mRNA, transcript and gene.
For these, the following applies:
- A gene annotation is generated for each gene_id. The region annotated extends from the leftmost to the rightmost positions of all annotations that have the gene_id (gtf-style).
- CDS annotations that have the same transcriptID are joined to one CDS annotation (gtf-style). Similarly, CDS annotations that have the same parent are joined to one CDS annotation (gff-style).
- If there is more than one exon annotation with the same transcriptID these are joined to one mRNA annotation. If there is only one exon annotation with a particular transcriptID, and no CDS with this transcriptID, a transcript annotation is added instead of the exon annotation (gtf-style).
- Exon annotations that have the same parent mRNA are joined to one mRNA annotation. Similarly, exon annotations that have the same parent transcript, are joined to one transcript annotation (gff-style).
For a comprehensive source of genomic annotation of genes and transcripts, we refer to the Ensembl web site at http://www.ensembl.org/info/data/ftp/index.html. On this page, you can download GTF files that can be used to annotate genomes for use in other analyses in the workbench. You can also read more about these formats at http://www.sanger.ac.uk/resources/software/gff/spec.html, http://mblab.wustl.edu/GTF22.html and https://genomebiology.biomedcentral.com/articles/10.1186/gb-2010-11-8-r88.
- GFF3
- A GFF3 file contains a list of various types of annotations that
can be linked together with "Parent" and "ID" tags. Learn more about how the
workbench handles GFF3 format in
GFF3 format.
- VCF
- This is the file format used for variants by the 1000 Genomes
Project and it has become a standard format. Read about VCF format here https://samtools.github.io/hts-specs/VCFv4.2.pdf. Learn how to access data at
http://www.1000genomes.org/data#DataAccess. Learn more about how the
workbench handles VCF format in
VCF format.
- BED
- Simple format for annotations. Read more at
http://genome.ucsc.edu/FAQ/FAQformat.html#format1. This format is
typically used for very simple annotations, for example target regions for
sequence capture methods. The file to import must have the first three columns (chromosome, start and end positions) matching the UCSC specifications. Remaining columns that do not match these requirements will be imported as Var1, Var2, etc.
- Wiggle
- The Wiggle format as defined by UCSC
(http://genome.ucsc.edu/goldenPath/help/wiggle.html) is used to
hold continuous data like conservation scores, GC content etc. When imported
into the CLC Genomics Workbench, a graph track is created. An example of a popular
Wiggle file is the conservation scores from UCSC which can be download for
human from
http://hgdownload.cse.ucsc.edu/goldenPath/hg19/phastCons46way/.
- UCSC variant database table dump
- Table dumps of variant
annotations from the UCSC can be imported using this option. Mainly files
ending with
.txt.gzon this list can be used: http://hgdownload.cse.ucsc.edu/goldenPath/hg19/database/. Please note that importer is for variant data and is not a general importer for all annotation types. This is mainly intended to allow you to import the popular Common SNPs variant set from UCSC. The file can be downloaded from the UCSC web site here: http://hgdownload.cse.ucsc.edu/goldenPath/hg19/database/snp138Common.txt.gz. Other sets of variant annotation can also be downloaded in this format using the UCSC Table Browser. - COSMIC variation database
- This lets you import the COSMIC database, which is a well-known publicly available primary
database on somatic mutations in human cancer. The file can be downloaded from the UCSC web site here:
http://cancer.sanger.ac.uk/cancergenome/projects/cosmic/download,
Users must first register to download the database. Import the file as a track. Through
Import->Tracks we support certain COSMIC databases in tsv format that can be
manually downloaded from the COSMIC ftp site:
- COSMIC Complete mutation data: CosmicCompleteTargetedScreensMutantExport.tsv
- COSMIC Mutation Data (Genome Screens): CosmicGenomeScreensMutantExport.tsv
- COSMIC Mutation Data : CosmicMutantExport.tsv
- All Mutations in Census Genes : CosmicMutantExportCensus.tsv
- COSMIC Complete mutation data: CosmicCompleteTargetedScreensMutantExport.tsv
Please see Annotation and variant formats for more information on how different formats (e.g. VCF and GVF) are interpreted during import in CLC format. For all of the above, zip files are also supported. Please note that for human data, there is a difference between the UCSC genome build and Ensembl/NCBI for the mitochondrial genome. This means that for the mitochondrial genome, data from UCSC should not be mixed with data from other sources (see http://hgdownload.soe.ucsc.edu/goldenPath/hg19/bigZips/). Most of the data above is annotation data and if the file includes information about allele variants (like VCF, Complete Genomics and GVF), it will be combined into one variant track that can be used for finding known variants in your experimental data. When the data cannot be recognized as variant data, one track is created for each annotation type. Genome / gene annotation tracks can be automatically imported from relevant databases as described here: http://resources.qiagenbioinformatics.com/manuals/clcgenomicsworkbench/current/index.php?manual=Selecting_data_types_download.html.
For all types of files except fasta, you need to select a reference track as well. This is because most the annotation files do not contain enough information about chromosome names and lengths which are necessary to create the appropriate data structures.
Subsections