SNP tree output report
The Create SNP Tree tool can optionally output a report that summarizes the consequence of the applied filtering settings, as well as a summary of ignored positions attributed to the different read mappings.
The first section of the report, "Filter Status", contains the actual counts found during analysis. The different categories are described below:
- Number of different input positions corresponds to the number of unique positions based on SNPs (and MNVs if selected).
- Pruned count reflects the number of positions pruned based on the specified filter value (see above).
- Coverage filtered count reflects the number of positions filtered based on the two specified filter values (see above).
- Z-value filtered count reflects the number of positions filtered based on the specified filter value (see above).
- Number of input positions used the final number of positions that passed all filtering steps and used for creating the SNP tree.
The second section consists of a graphical and a tabular representation of the number of positions that was filtered because of the individual read mappings. The tabular view has three columns:
- Read mapping. The name of the read mapping.
- Filtered, total. The total number of filtered positions contributed by this read mapping, i.e. how many positions in this read mapping where either the coverage was too low, or the z-score was too low. Note that several read mappings can contribute the same position.
- Filtered, only by this. The number of filtered positions contributed only by this read mapping, i.e. the number of positions that was filtered by this read mapping, and not filtered by any other read mappings.
In the example below, we are creating a tree based on three read mappings, mapping 1, mapping 2 and mapping 3.
- Mapping 1 has low coverage on positions a, b and c.
- Mapping 2 has low coverage on positions a, b, d and e.
- Mapping 3 has low coverage on positions a, b and e.
In this case
- Mapping 1 will have a "Filtered, total" count of 3 (positions a, b and c), and a "Filtered, only by this" count of 1 (position c).
- Mapping 2 will have a "Filtered, total" count of 4 (positions a, b, d and e) and a "Filtered, only by this" count of 1 (position d).
- Mapping 3 will have a "Filtered, total" count of 3 (positions a, b and e) and a "Filtered, only by this" count of 0.
We will get a table like this:
| Read mapping | Filtered, total | Filtered, only by this |
| Mapping 1 | 3 | 1 |
| Mapping 2 | 4 | 1 |
| Mapping 3 | 3 | 0 |
An example of report content shown in figures 11.7, 11.8, 11.9 and 11.10.
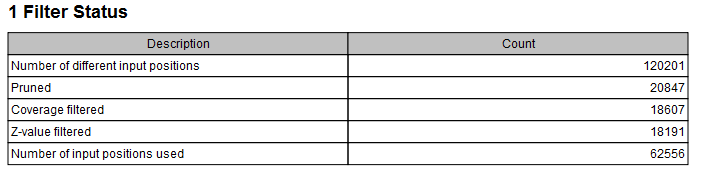
Figure 11.7: Report on Filter Status for the created SNP tree.
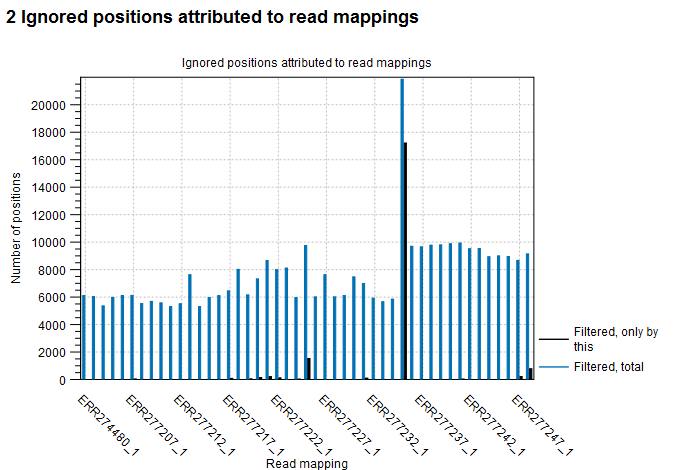
Figure 11.8: Visualization of the filter effect across data used for generation of SNP tree.
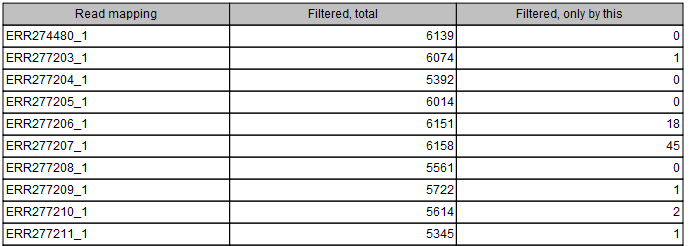
Figure 11.9: Listing filtering results of the first 10 rows of the 47 rows of the data sets. Each row show the number of ignored positions generally across all data set as well as number of ignored positions when filtering on the particular data set only.
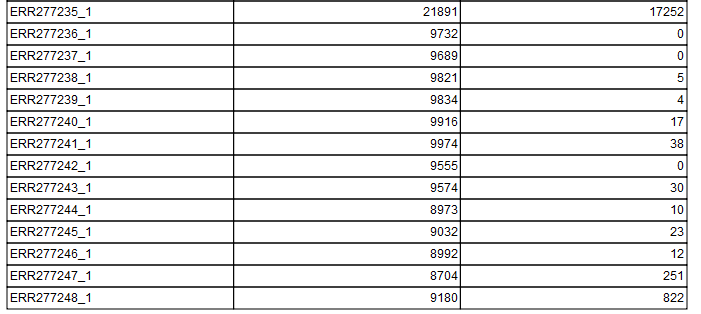
Figure 11.10: Listing filtering results of the last 14 rows of the 47 rows of the data sets. Each row show the number of ignored positions generally across all data set as well as number of ignored positions when filtering on the particular data set only. The tabular information indicates that sample acc no ERR277235_1 shows significantly lower quality than the other samples.
In the applied example, ERR277235_1 shows significantly higher number of positions ignored than the other samples (see figures 11.8 and 11.10), and one might consider rerunning the tree without this sample in an attempt to get a higher resolution in the tree.