Interpreting the output of QC for Single Cell
Because the distribution of the QC metrics can be sample-specific, QC for Single Cell runs separately for each sample detected in the input Expression Matrix, producing the following outputs:
- A single Expression Matrix (
 ) / (
) / ( ) containing only the barcodes that passed all filters.
) containing only the barcodes that passed all filters.
- A single Cell Annotations (
 ) element containing the different QC metrics used by the filters for the barcodes that passed all filters. Using this Cell Annotations, the barcodes can be colored in a Dimensionality Reduction Plot plot (see Dimensionality reduction) using the QC metrics.
) element containing the different QC metrics used by the filters for the barcodes that passed all filters. Using this Cell Annotations, the barcodes can be colored in a Dimensionality Reduction Plot plot (see Dimensionality reduction) using the QC metrics.
- A Report (
 ) per sample, summarizing the filters applied and providing diagnostic plots for each type of filter, as detailed below.
) per sample, summarizing the filters applied and providing diagnostic plots for each type of filter, as detailed below.
Empty droplets filter
Note that for droplet-based protocols, each droplet is assigned one barcode and these terms can be used interchangeably.
If the Empty droplets filter was enabled, the report contains the following information.
The report first shows the barcode rank plot, as seen in figure 5.9.
![]()
Figure 5.9: Barcode rank plot: log-log plot of the total number of reads for each barcode vs the rank of the barcode, in decreasing order of the number of reads. The barcodes are colored according to whether they are empty droplets containing only ambient RNA (Ambient, black) or retained as cells because they contain a high number of reads (Retained, green). When "Identify cells from the remaining droplets" is enabled, remaining barcodes are shown in blue and are tested for being empty droplets (top). Otherwise, these barcodes are shown in red and are removed as empty droplets (bottom).
A summary of the empty droplet filtering and the identified cells is then shown, see figure 5.10.
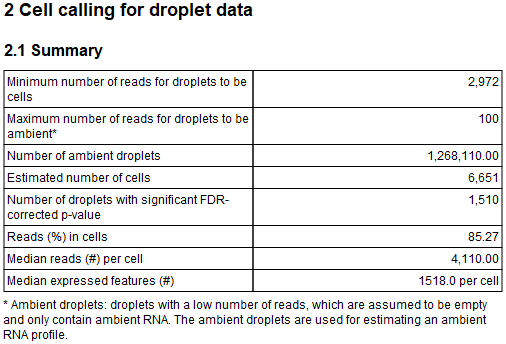
Figure 5.10: Table summarizing the performed empty droplets filter and identified cells. "Number of droplets with significant FDR-corrected p-value" is reported only when "Identify cells from the remaining droplets" is enabled.
If any automatic threshold was used (see Empty droplets filter), the barcode rank plot and summary table can indicate if this was successful or not. If any of the thresholds are not appropriate, they can be changed as detailed in Empty droplets filter.
When Identify cells from the remaining droplets is enabled, the p-values are simulation-based. The number of simulations to be performed is calculated automatically based on the FDR threshold. The report shows the p-value distribution for the ambient droplets. This is expected to be roughly uniformly distributed. Peaks close to 0 indicate that the assumption is invalid and the value for considering barcodes as being empty droplets should be reduced (see Empty droplets filter).
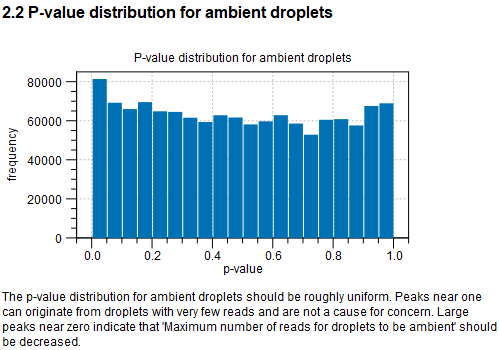
Figure 5.11: Histogram of the p-values calculated for the barcodes from which the ambient RNA profile is built.
Count-based and extra-chromosomal filters
If the Empty droplets filter was not enabled, the report first shows the barcode rank plot, as seen in figure 5.12.
![]()
Figure 5.12: Barcode rank plot: log-log plot of the total number of reads for each barcode vs the rank of the barcode, in decreasing order of the number of reads. The barcodes are colored according to whether they are removed (red) or retained (blue), as determined by the number of reads filter.
The report then lists various summaries regarding the performed Count-based filters and Extra-chromosomal filters, as shown in figure 5.13.
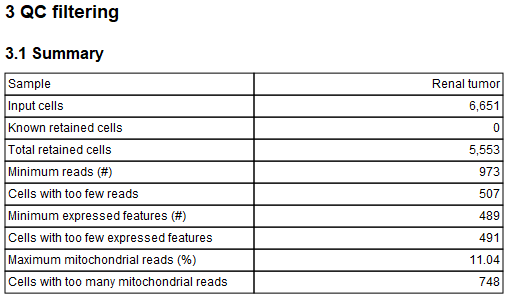
Figure 5.13: Table summarizing the performed count-based and extra-chromosomal filters.
Following are histograms of all QC metrics, regardless whether they have been used for filtering or not. When filtering was enabled, the histograms indicate the threshold used, see figure 5.14. When this threshold is calculated automatically based on the MAD (see Count-based and extra-chromosomal filters), the histograms can indicate if the threshold is appropriate or not.
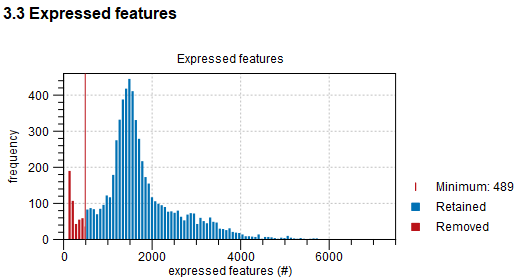
Figure 5.14: Histogram of the number of expressed features for all barcodes.
When the mitochondria filter is enabled, barcodes with too many reads mapped to the mitochondria are removed. However, high quality cells can be highly metabolically active, leading to the incorrect removal of barcodes. The report shows relations between the number of reads mapped to the mitochondria and the other QC metrics, to help identify such barcodes. Using the MAD approach (see Count-based and extra-chromosomal filters), the report attempts to automatically highlight such barcodes, but it is conservative in doing so. This can be seen in figure 5.15, where only two barcodes with a relatively high number of expressed features are highlighted, due to the shape of the underlying distribution shown in figure 5.14. See Choosing barcodes to retain on how to specify barcodes that should not be removed.
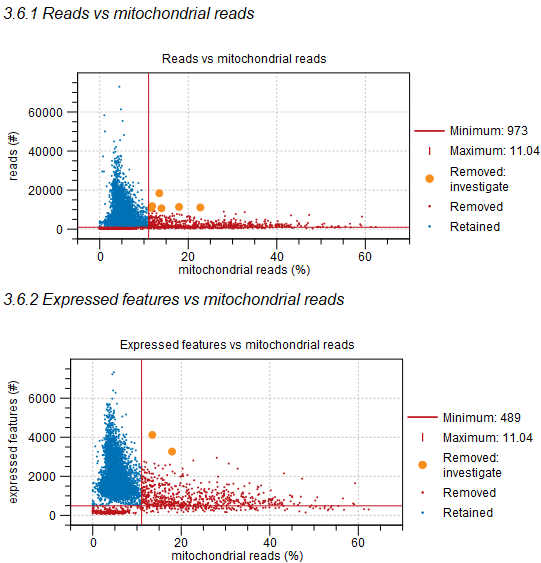
Figure 5.15: The number of reads mapped to the mitochondria vs the total number of reads (top) and expressed features (bottom). Barcodes in red have been removed and those in blue have been retained. The thresholds for removing barcodes are shown as horizontal and vertical red lines. Barcodes highlighted in orange have been removed, but might correspond to high quality cells that are highly metabolically active that should be retained.
Doublets filter
If the Doublets filter was enabled, the report contains the following information.
The report first lists a few summaries regarding the performed filter and the identified cells, as shown in figure 5.16.
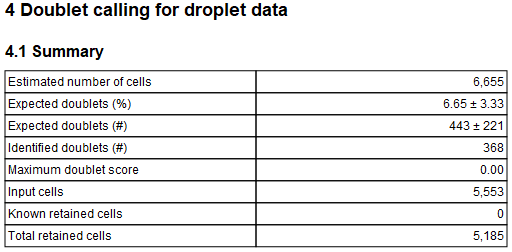
Figure 5.16: Table summarizing the performed doublets filter and identified cells.
Following is a histogram showing the doublet scores (see figure 5.17), which can indicate if doublet filtering was successful.
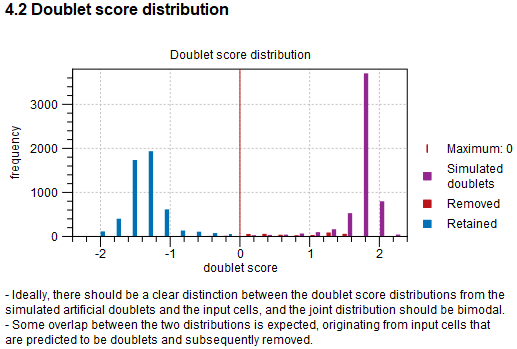
Figure 5.17: Histogram of the doublet score for all barcodes and simulated artificial doublets. The histogram is in dodge format: the width of one bin is given by the sum of the widths of the three types of shown data. The threshold for removing barcodes is shown as a vertical red line.
The report also shows relations between the doublet score and number of reads and expressed features (see figure 5.18). Typically, barcodes with a high number of expressed features and / or number of reads are more likely do be removed as doublets.
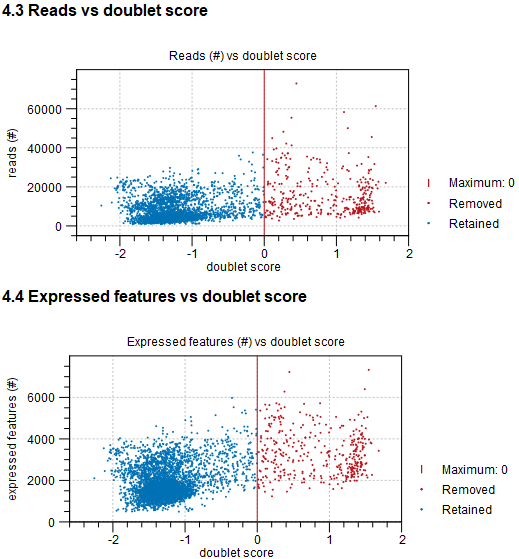
Figure 5.18: The doublet score vs the total number of reads (top) and expressed features (bottom). Barcodes in red have been removed and those in blue have been retained. The threshold for removing barcodes is shown as vertical red lines.
These diagnostic plots can serve as a guide in adjusting the options for the doublet filter.