Translation of DNA or RNA to protein
In CLC Genomics Workbench you can translate a nucleotide sequence into a protein sequence using the Toolbox tools. Usually, you use the +1 reading frame which means that the translation starts from the first nucleotide. Stop codons result in an asterisk being inserted in the protein sequence at the corresponding position. It is possible to translate in any combination of the six reading frames in one analysis. To translate, go to:
Toolbox | Classical Sequence Analysis (![]() ) | Nucleotide Analysis (
) | Nucleotide Analysis (![]() )|
Translate to Protein (
)|
Translate to Protein (![]() )
)
This opens the dialog displayed in figure 14.5:
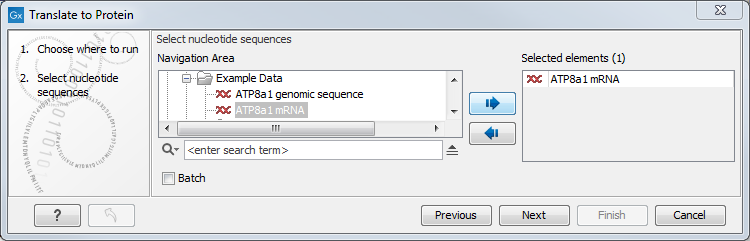
Figure 14.5: Choosing sequences for translation.
If a sequence was selected before choosing the Toolbox action, the sequence is now listed in the Selected Elements window of the dialog. Use the arrows to add or remove sequences or sequence lists from the selected elements.
Clicking Next generates the dialog seen in figure 14.6:
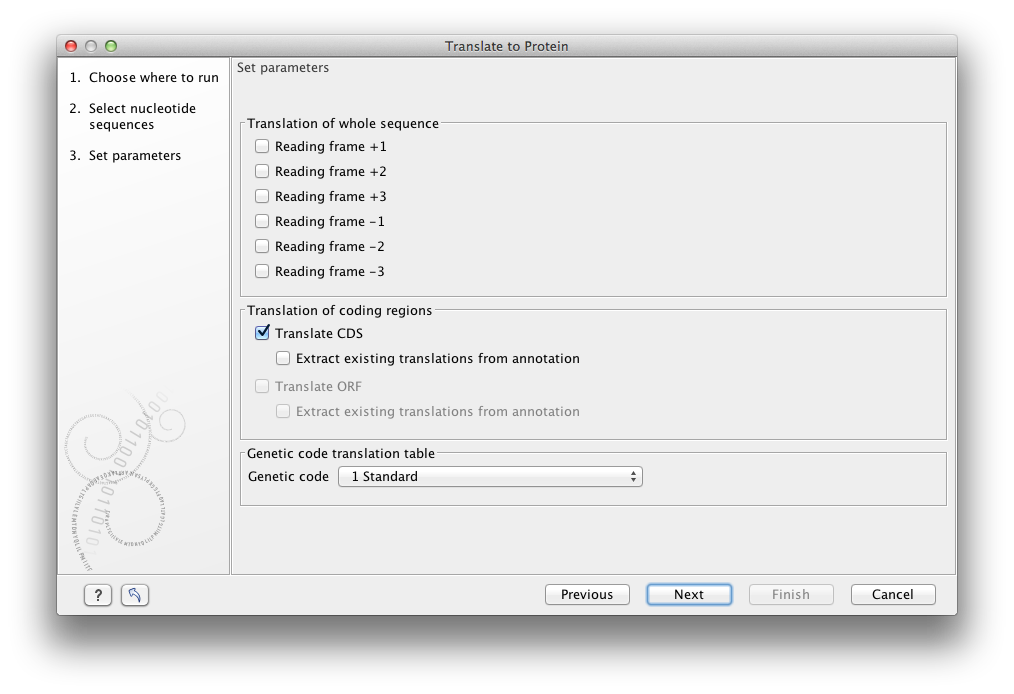
Figure 14.6: Choosing translation of CDS's using standard translation table.
Here you have the following options:
- Reading frames
- If you wish to translate the whole sequence, you must specify the reading frame for the translation. If you select e.g. two reading frames, two protein sequences are generated.
- Translate CDS
- You can choose to translate regions marked by and CDS or ORF annotation. This will generate a protein sequence for each CDS or ORF annotation on the sequence. The "Extract existing translations from annotation" allows to list the amino acid CDS sequence shown in the tool tip annotation (e.g. interstate from NCBI download) and does therefore not represent a translation of the actual nt sequence.
- Genetic code translation table
- Lets you specify the genetic code for the translation. The translation tables used are listed in here.
Click Finish to start the tool. The newly created protein is shown, but is not saved automatically.
To save a protein sequence, drag it into the Navigation Area or press Ctrl + S (![]() + S on Mac) to activate a save dialog.
+ S on Mac) to activate a save dialog.
The name for a coding region translation consists of the name of the input sequence followed by the annotation type and finally the annotation name.
Translate part of a nucleotide sequence
If you want to make separate translations of all the coding regions of a nucleotide sequence, you can check the option: "Translate CDS and ORF" in the translation dialog (see figure 14.6).
If you want to translate a specific coding region, which is annotated on the sequence, use the following procedure:
Open the nucleotide sequence | right-click the
ORF or CDS annotation | Translate
CDS/ORF (![]() ) | choose a translation table |
OK
) | choose a translation table |
OK
If the annotation contains information about the translation, this information will be used, and you do not have to specify a translation table.
The CDS and ORF annotations are colored yellow as default.