The Identify TMB Status ready-to-use workflows
The Identify QIAseq DNA Somatic Variants with TMB Score (Illumina) or (Ion Torrent) has been designed to support the DHS-8800Z and DHS-6600Z QIAseq Targeted DNA panels. These panels cover a significantly larger region of the genome than classic Targeted DNA panels, which increases the difficulty of variant calling especially with regards to specificity. Through a series of tools and filters, the Identify TMB Status ready-to-use workflow has the ability to accurately call variants and to compute a TMB score and score confidence that can be classified as low, intermediate or high.
To run the workflow outside of the Analyze QIAseq Panels guide, go to:
Ready-to-Use Workflows | QIAseq Panel Analysis | QIAseq Analysis workflows | Identify QIAseq DNA Somatic Variants with TMB Score (Illumina/Ion Torrent) (![]() )
)
If you are connected to a CLC Server via your Workbench, you will be asked where you would like to run the analysis. We recommend that you run the analysis on a CLC Server when possible.
You can then select the reads to analyze (figure 3.12).
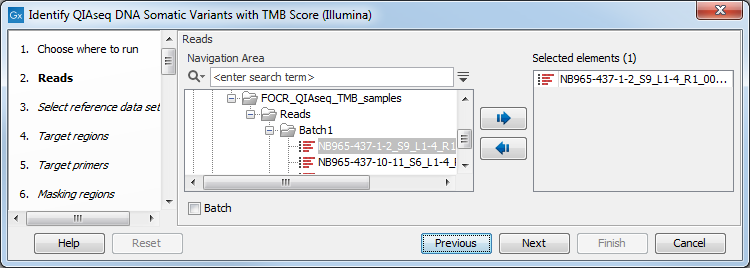
Figure 3.12: Choose the reads sequenced with a Tumor Mutational Burden QIAseq Targeted DNA panel.
The next dialog helps you specify the QIAseq TMB Panels hg38 Reference Data Set needed to run the workflow. If you have not downloaded this Reference Data Set yet, it is possible to do so in this dialog as well (figure 3.13).
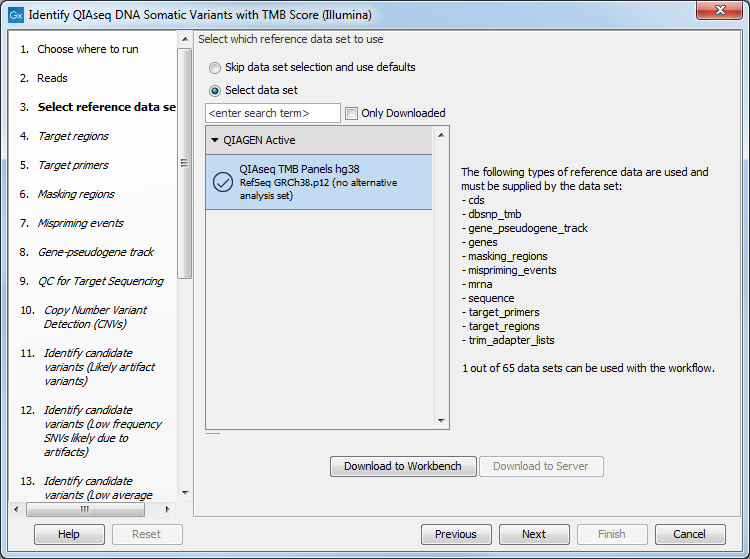
Figure 3.13: Choose the appropriate Reference Data Set.
In the Target regions dialog, select from the drop-down menu the track corresponding to the panel used to generate the reads analyzed (figure 3.14).
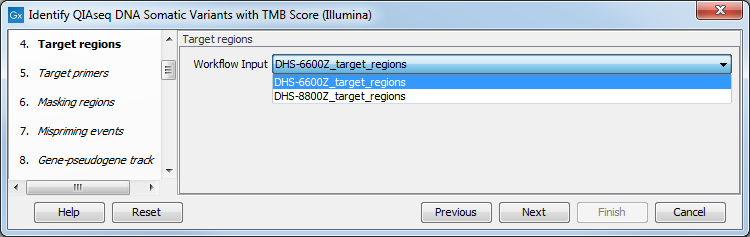
Figure 3.14: Choose the relevant Target regions track from the drop-down menu.
Repeat the selection of the appropriate track for Target primers, Masking regions, Mispriming events and Gene-pseudogene in the subsequent dialogs.
In the QC for Target Sequencing dialog, choose what minimum coverage is required for a variant to be considered of interest (figure 3.15). Variants whose coverage is below this value will be filtered out.
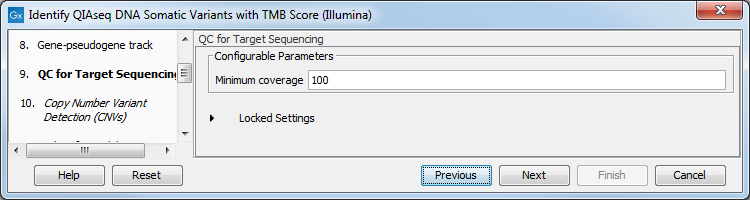
Figure 3.15: Configuring the QC for Target Sequencing tool.
In the Copy Number Variant Detection (CNVs) dialog, you can specify a control mapping against which the coverage pattern in your sample will be compared in order to call CNVs. In this case, the output of the workflow will include the results of the CNV Detection tool, allowing you to get a better understanding of the sample in a single run (figure 3.16). If you do not specify a control mapping the Copy Number Variation analysis will not be carried out.
Figure 3.16: CNV Detection can be performed simultaneously if a control mapping is provided at this step.
An appropriate control mapping can be found in the Navigation Area of the Workbench if the workflow was previously run with control data. In this case, the control mapping will be saved in the Reports and Data folder (Mapped UMI Reads) of that control analysis. Please note that if you want the copy number variation analysis to be carried out, it is very important that the control mapping that you supply the tool with is meaningful as a control for the sample that you are analyzing.
A meaningful control must satisfy two things: it must (1) have a copy number status that it is meaningful for you to compare your sample against and (2) it must be a read mapping that has been processed in the same manner that your sample has been processed. To ensure (1), it is important for panels with targets on the X and Y chromosomes that the control and sample are of the same gender. You can ensure (2) by processing the sample that you want to use as control with the workflow (without control mapping to the CNV detection component) and use the resulting UMI reads track as controls in subsequent runs of the workflow.
Next, a series of filters will remove variants that are either:
- not significant enough: filtering is performed based on the QUAL value, value that weighs count against coverage and error rate.
- likely due to artifacts: a called variant must be of sufficient quality, and have an un-biased read direction or read position presence (using the values "Average quality", "Read position test probability" and "Read direction test probability").
- homopolymer errors (indels occuring in a homopolymer stretch) using a too low frequency cut-off value.
- too infrequent.
These filters only remove alternative alleles - and not reference alleles - as this potentially leads to wrong interpretation of variants by the VCF exporter where such variants could be misinterpreted as hemizygote when the reference allele is missing.
Another series of filtering will also take place just before TMB score calculation. In particular, the tool Calculate TMB Score will remove, among others, germlines variants based on frequencies as well as known germline variants from dbSNP.
Note that each filter has been configured with specific default values depending on the technology (Illumina / Ion torrent) chosen to provide the best sensitivity and precision in the variants output by each workflow. However, benchmarking was performed on samples of relatively high coverage. Therefore, additional filtering might be needed, or filtering values adjusted when working with low coverage samples. This can only be done by running the workflows listed in the Toolbox, and not by using the panel guide. When configuring filters, do not load any annotations or try to change the name of the filters in the first column, as it would disable the filter completely.
Finally, in the Add Information about Amino Acid Changes, leave the genetic code set to 1 Standard before specifying where you would like the results of the workflow to be saved.
Subsections