Defining mapping options for RNA-Seq
When the reference has been defined, click Next and you are presented with the dialog shown in figure 29.5.
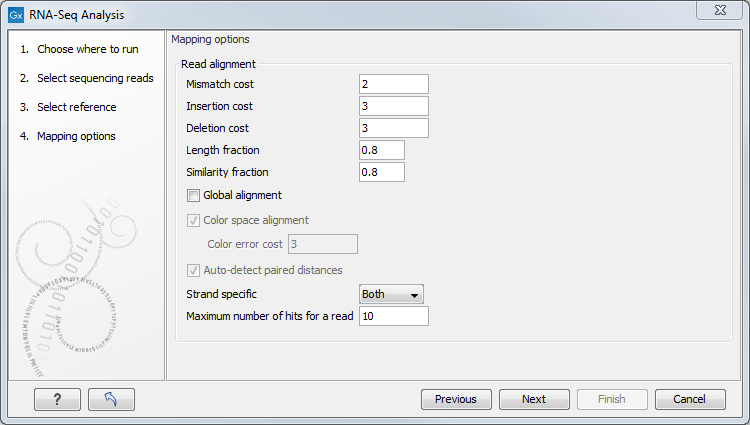
Figure 29.5: Defining mapping parameters for RNA-Seq.
The mapping parameters are identical to those applying to Map Reads to Reference, as the underlying mapping is performed in the same way. For a description of the parameters, please see Mapping parameters.
For the estimation of paired reads distances, RNA-Seq uses the transcript level reference sequence information. This means that introns are not included in the distance measurement. The paired distance measurement will only include transcript sequence, reflecting the true nature of the sequence on which the paired reads were produced.
In addition to the generic mapping parameters, two RNA-Seq specific parameters can be set:
- Maximum number of hits for a read. A read that matches equally well to more distinct places in the references than the 'Maximum number of hits for a read' specified will not be mapped (the notion of distinct places is elaborated below). If a read matches to multiple distinct places, but less than the specified maximum number, it will be randomly assigned to one of these places. The random distribution is done by the EM algorithm (see EM estimation algorithm)
The definition of a distinct place in the references is complicated because each annotated transcript is extracted and used as reference for the read mapping (if the "Genome annotated with genes and transcripts" is selected in figure 29.4). To exemplify, consider a gene with 10 transcripts and 11 exons, where all transcripts have exon 1, and each of the 10 transcripts have only one of the exons 2 to 11. Exon 1 will be represented 11 times in the references (once for the gene region and once for each of the 10 transcripts). Reads that match to exon 1 will thus match to 11 of the extracted references. However, when the mappings are considered in the coordinates of the main reference genome, it becomes evident that the 11 match places are not distinct but in fact identical. In this case this will just count as one distinct placement of the read, and it will not be discarded for exceeding the maximum number of hits limit. Similarly, when a multi-match read is randomly assigned to one of its match places, each distinct place is considered only once.
The limit for how many non-specific matches a read is allowed to have is applied first to the set of gene matches (if any), and then to intergenic matches. As an example using the default value of 10, if a read matches equally well 8 places within genes and 50 places in intergenic regions, it is still considered a valid match. It will only be discarded if the number of matches within genes is above the limit, or if there are no gene matches at all and the number of intergenic matches exceeds the limit.
Note that, although a read is mapped distinctly at the gene level, it does not necessarily map uniquely to a particular transcript of the gene. The above example with a gene with 10 transcripts and 11 exons, where all transcripts have exon 1, and each of the 10 transcripts have only one of the exons 2 to 11, is a good and easy to understand example of this: all reads that are mapped to exon 1 are uniquely mapped at the gene level but are non-specific matches at the transcript level. A more complicated example is that you may have a gene with transcript annotations where one transcript has a longer version of an exon than the other. In this case you may have reads that may either be mapped entirely within the long version of the exon, or across the exon-exon boundary of one of the transcripts with the short version of the exon. Such an example is provided by the gene 'Ftl1' in the example below (gene and mRNA annotations for that gene are shown in figure 29.6, along with the reads mapping to the gene).

Figure 29.6: The gene 'Ftl1' from the mouse chromosome 7.When you zoom in on the regions at the end of the second exons and the beginning of the third exons (Figure 29.7) you see that the reference sequence is identical in the start of the part of the second exons that is only present in the long version, and in the start of the third exons (they share the sequence 'CTGCACA'). So a read that is '...TCATCTTGAGATGGCTTCTGCACA' may be either mapped entirely within the long version of the second exons, or across the exon-exon boundary of the short version of the second exon and the third exon. For reporting expression levels at the transcript level, reads are assigned among the transcripts to which they map by the Expectation Maximization algorithm.
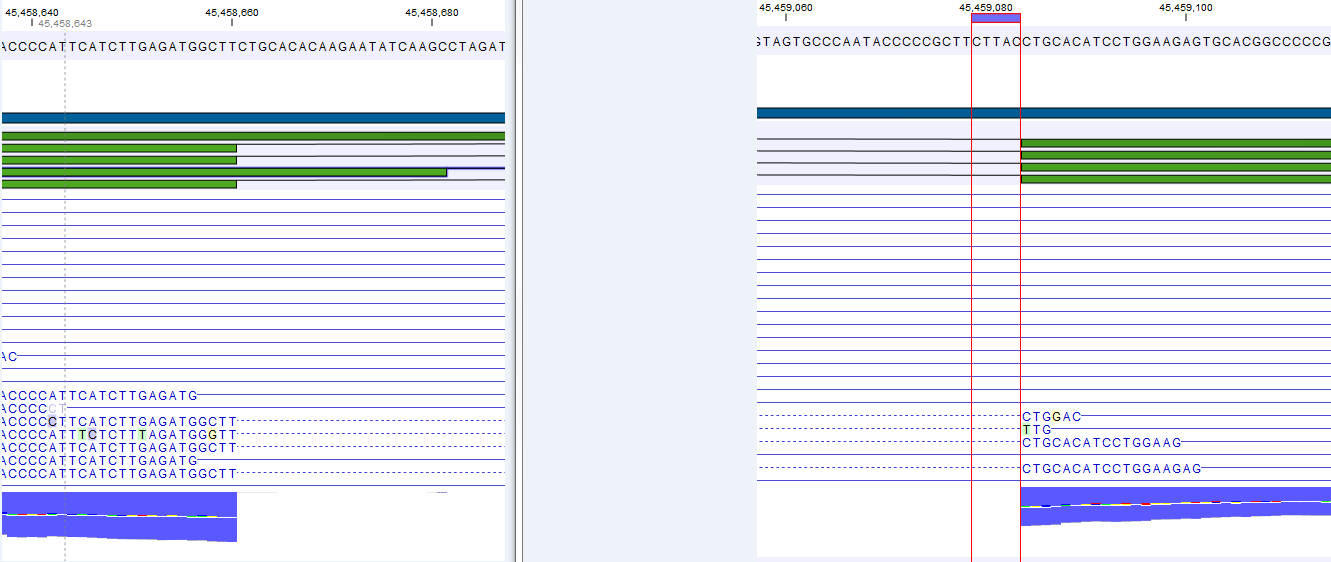
Figure 29.7: The regions at the end of the second exons and the beginning of the third exons of the mRNA transcripts for the gene 'Ftl1'. - Strand-specific alignment. When this option is checked, the user can specify whether the reads should be mapped in the same orientation as the transcript from which they originate (forward) or in the reverse direction (reverse). This will typically be appropriate when a strand specific protocol for read generation has been used. It allows assignment of the reads to the right gene in cases where overlapping genes are located on different strands. Without the strand-specific protocol, this would not be possible (see [Parkhomchuk et al., 2009]). Note that when running RNA seq with the strand specific option turned on you can only make use of pairs in forward-reverse orientation, meaning that mate pairs are not supported.