Perform QIAseq Multimodal Analysis (Illumina) template workflow
The Perform QIAseq Multimodal Analysis (Illumina) template workflow is intended for the analysis of QIAseq Multimodal RNA and DNA samples generated using the combined lab protocol.
The workflow is built by combining variant calling from the Identify QIAseq DNA Somatic Variants (Illumina) workflow and fusion detection from the Perform QIAseq RNAscan Fusion XP workflow, with some minor adjustments. Specifically, two tools to further annotate variants have been added:
- Annotate RNA Variants
- Annotate with Repeat and Homopolymer Information, described at http://resources.qiagenbioinformatics.com/manuals/clcgenomicsworkbench/current/index.php?manual=Annotate_with_Repeat_Homopolymer_Information.html.
The annotations added by these tools are used to filter away variant calls that most likely origin from RNA contamination and variants appearing within repeat or homopolymer regions.
The workflow can be run with the Reference Data Set QIAseq Multimodal Panels hg38. This set contains Catalog Panel Primers and Target Regions that have been lifted to the hg38 reference sequence. You can either download the reference data set before starting the analysis or download the default data set during execution of the workflow.
The Perform QIAseq Multimodal Analysis (Illumina) template workflow can be found at:
Template Workflows | Biomedical Workflows (![]() ) | QIAseq Sample Analysis (
) | QIAseq Sample Analysis (![]() ) | QIAseq Analysis workflows (
) | QIAseq Analysis workflows (![]() ) | Perform QIAseq Multimodal Analysis (Illumina) (
) | Perform QIAseq Multimodal Analysis (Illumina) (![]() )
)
Double-click on Perform QIAseq Multimodal Analysis (Illumina) to run the workflow.
If you are connected to a CLC Server via your Workbench, you will be asked where you would like to run the analysis. We recommend that you run the analysis on a CLC Server when possible.
The panel in the left-hand side of the dialog allows you to keep track of the steps, you will be going through before being able to launch the analysis. First, specify the DNA sequencing reads that should be analyzed (figure 9.1).
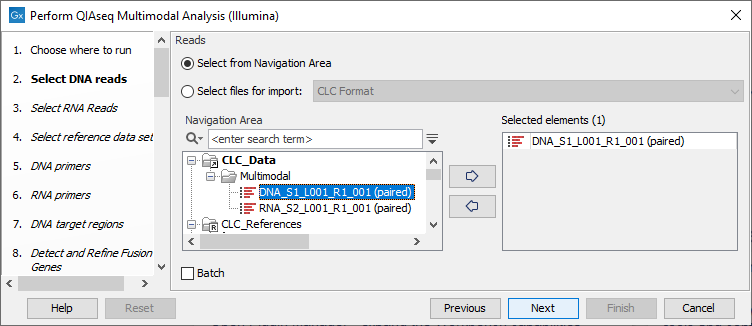
Figure 9.1: Select the DNA sequencing reads by double-clicking on the file name or by clicking once on the file name and then on the arrow pointing to the right-hand side.
Next, specify the RNA sequencing reads (figure 9.2).
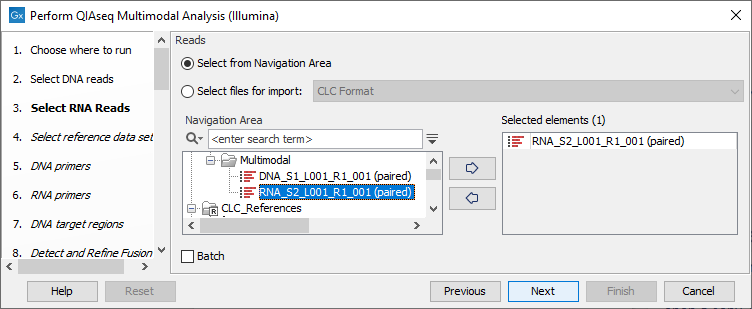
Figure 9.2: Select the RNA sequencing reads by double-clicking on the file name or by clicking once on the file name and then on the arrow pointing to the right-hand side.
The following dialog helps you set up the relevant Reference Data Set. If you have not downloaded the Reference Data Set yet, the dialog will suggest the relevant data set and offer the opportunity to download it using the Download to Workbench button. (figure 9.3).
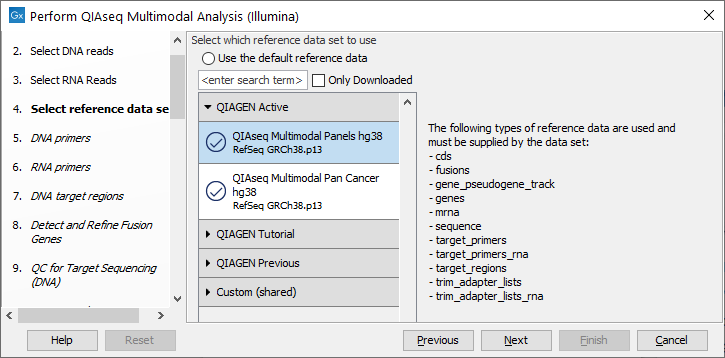
Figure 9.3: The relevant Reference Data Set is highlighted; in the text to the right, the types of reference needed by the workflow are listed.
Note that if you wish to Cancel or Resume the Download, you can close the template workflow and open the Reference Data Manager where the Cancel, Pause and Resume buttons are available.
If the Reference Data Set was previously downloaded, the option "Use the default reference data" is available and will ensure the relevant data set is used. You can always check the "Select a reference set to use" option to be able to specify another Reference Data Set than the one suggested.
In the next three dialogs, you are asked to select the DNA and RNA primers and the DNA target regions from the available catalog panels. Select the appropriate catalog number from the drop-down list. For custom datasets usually only one option is available.
In the Detect and Refine Fusion Genes dialog, it is possible to change the Promiscuity threshold, i.e., the maximum number of different fusion partners reported for a gene. You can also check for exon skippings by enabling the Detect exon skippings option, as well as check for fusions with novel exon boundaries by enabeling the Detect fusions with novel exon boundaries option. This dialog is shown in figure 9.4
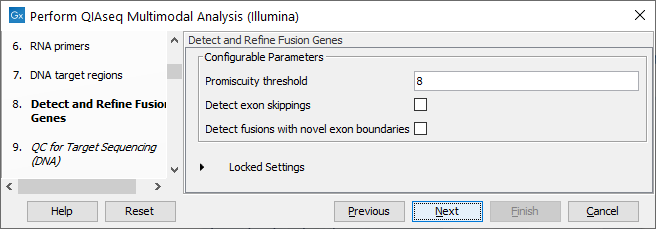
Figure 9.4: The Detect and Refine Fusion Genes dialog.
In the dialog called QC for Target Sequencing, you can modify the Minimum coverage needed on all positions in a target for this target to be considered covered. For somatic calling we recommend setting this no lower than 100x.
The dialog for Copy Number Variant Detection allows you to specify a control mapping against which the coverage pattern in your sample will be compared in order to call CNVs. If you do not specify a control mapping, or if the target regions files contains fewer than 50 regions, the Copy Number Variation analysis will not be carried out.
Please note that if you want the copy number variation analysis to be done, it is important that the control mapping supplied is a meaningful control for the sample being analyzed. Mapping of control samples for the CNV analysis can be done using the workflows described in Create QIAseq DNA CNV Control Mapping workflows.
A meaningful control must satisfy two conditions: (1) It must have a copy number status that it is meaningful for you to compare your sample against. For panels with targets on the X and Y chromosomes, the control and sample should be matched for gender. (2) The control read mapping must result from the same type of processing that will be applied to the sample. One way to achieve this is to process the control using the workflow (without providing a control mapping for the CNV detection component) and then to use the resulting UMI reads track as the control in subsequent workflow runs.
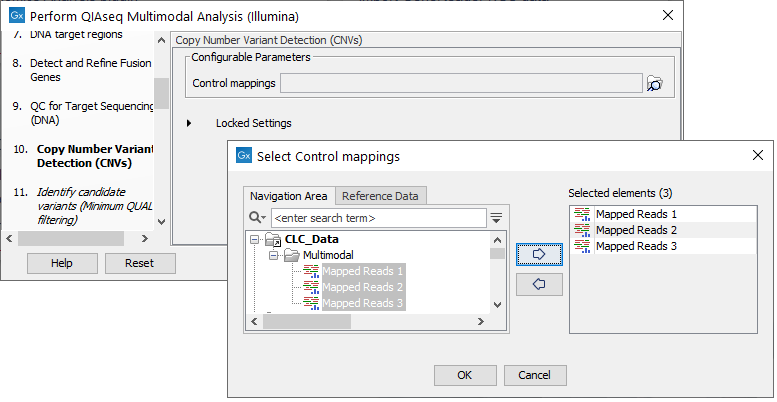
Figure 9.5: The Copy Number Variation Detection dialog. Here three control samples have been selected. In practice it is recommended to either use a matched control sample, or to use at least five control samples. Increasing the number of samples beyond this does not typically improve results.
The parameters for variant detection are not adjustable and have been set to generate an initial pool of all potential variants. These are then passed through a series of filters to remove variants that are suspected artifacts. Variants failing to meet the (adjustable) thresholds for quality, read direction bias, location (low frequency indels within homopolymer stretches), frequency or coverage would not be included in the filtered output.
Some filters only remove alternative alleles - and not reference alleles - as this potentially leads to wrong interpretation of variants by the VCF exporter where such variants could be misinterpreted as hemizygote when the reference allele is missing.
Finally, in the last wizard step, choose to Save the results of the workflow and specify a location in the Navigation Area before clicking Finish to launch the analysis.
Subsections