Identify Variants (WES)
The Identify Variants (WES) workflow takes sequencing reads as input and returns identified variants as part of a Track List.
The tool runs an internal workflow, which starts with mapping the sequencing reads to the human reference sequence, followed by removal of duplicate mapped reads (to reduce biases introduced by target enrichment). The resulting read mapping is analyzed by the Structural Variant Caller to infer indels and other structural variants from unaligned end read patterns. Subsequently, the mapping is realigned, guided by the indels detected by the Structural Variant Caller. The locally realigned read mapping is analyzed by the Low Frequency Variant Detection tool. The Low Frequency Variant Detection tool produces a track of unfiltered variants; these are subjected to a number of post filters to remove variants that are likely due to artifacts or noise. The variants called by the Low Frequency Variant Detection tool that pass the post filtering criteria can be found in the Identified variants track. Variants inferred by the Structural Variant Caller, and not detected by the Low Frequency Variant Detection tool, are also subjected to a number of post filters; those that pass the post filter criteria can be found in the Indels indirect evidence track.
In addition, a targeted region report is created to inspect the overall coverage and mapping specificity in the targeted regions.
Before starting the workflow, you will need to import in the workbench a file with the genomic regions targeted by the amplicon or hybridization kit. Such a file (a BED or GFF file) is usually available from the vendor of the enrichment kit and sequencing machine. Use the Import | Tracks tool to import it in your Navigation Area.
Run the Identify Variants (WES) workflow
To run the Identify Variants (WES) workflow, go to:
Template Workflows | Biomedical Workflows (![]() ) | Whole Exome Sequencing (
) | Whole Exome Sequencing (![]() ) | Somatic Cancer (
) | Somatic Cancer (![]() ) | Identify Variants (WES) (
) | Identify Variants (WES) (![]() )
)
- Select the sequencing reads from the sample that should be analyzed (figure 22.31).
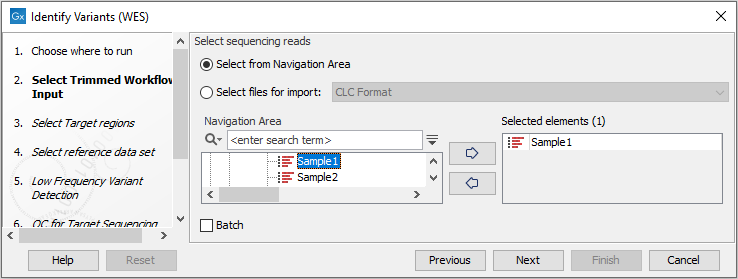
Figure 22.31: Please select all sequencing reads from the sample to be analyzed.If several samples should be analyzed, the tool has to be run in batch mode. This is done by checking "Batch" and selecting the folder that holds the data you wish to analyze.
- Next, in the Target regions dialog you need to specify the target regions for your application. The variant calling will be restricted to these regions (figure 22.32).
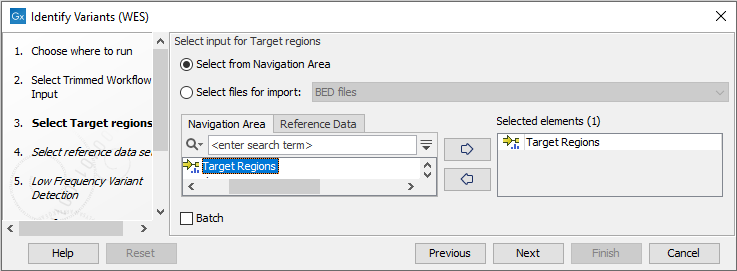
Figure 22.32: Select the track with the targeted regions from your experiment. - In the next dialog, you have to select which reference data set should be used to identify variants (figure 22.33).
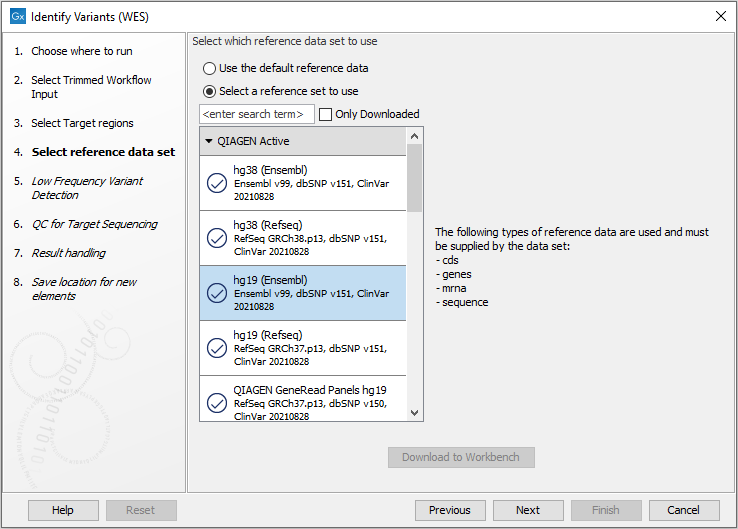
Figure 22.33: Choose the relevant reference Data Set to identify variants in your sample. - In the next wizard step (figure 22.34), you can specify the parameters for variant detection.
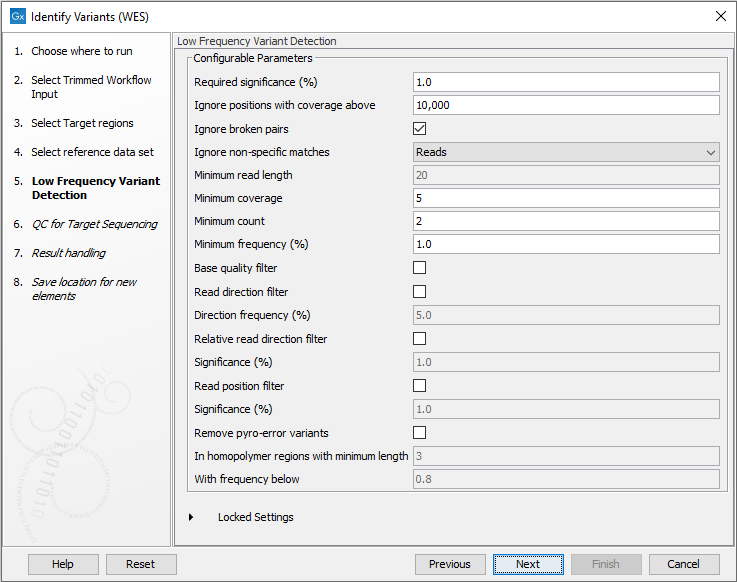
Figure 22.34: Specify the parameters for variant detection. - In the QC for Target Sequencing step (figure 22.35) you can specify the minimum read coverage, which should be present in the targeted regions.
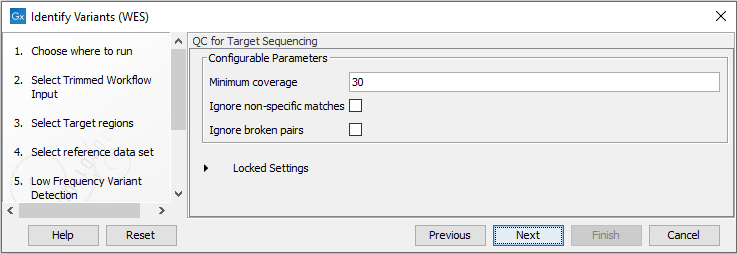
Figure 22.35: Specify the minimum coverage for the QC for Targeted sequencing. - In the last wizard step you can check the selected settings by clicking on the button labeled Preview All Parameters.
In the Preview All Parameters wizard you can only check the settings, and if you wish to make changes you have to use the Previous button from the wizard to edit parameters in the relevant windows.
- Choose to Save your results and click Finish.
Output from the Identify Variants (WES) workflow
The Identify Variants (WES) tool produces the following outputs:
- Read Mapping (
 ) The mapped sequencing reads. The reads are shown in different colors depending on their orientation, whether they are single reads or paired reads, and whether they map unambiguously (see http://resources.qiagenbioinformatics.com/manuals/clcgenomicsworkbench/current/index.php?manual=Coloring_mapped_reads.html).
) The mapped sequencing reads. The reads are shown in different colors depending on their orientation, whether they are single reads or paired reads, and whether they map unambiguously (see http://resources.qiagenbioinformatics.com/manuals/clcgenomicsworkbench/current/index.php?manual=Coloring_mapped_reads.html).
- Target Regions Coverage (
 ) The target regions coverage track shows the coverage of the targeted regions. Detailed information about coverage and read count can be found in the table format, which can be opened by pressing the table icon found in the lower left corner of the View Area.
) The target regions coverage track shows the coverage of the targeted regions. Detailed information about coverage and read count can be found in the table format, which can be opened by pressing the table icon found in the lower left corner of the View Area.
- Target Regions Coverage Report (
 ) The report consists of a number of tables and graphs that in different ways provide information about the targeted regions.
) The report consists of a number of tables and graphs that in different ways provide information about the targeted regions.
- Three variant tracks (
 ): Two from the Variant Caller: the Unfiltered Variants is output before the filtering steps, the Variants passing filters is the one used in the Genome Browser View (see
.
http://resources.qiagenbioinformatics.com/manuals/clcgenomicsworkbench/current/index.php?manual=_annotated_variant_table.html for a definition of the variant table content). The third is the Indels indirect evidence track produced by the Structural Variant Caller. This is also available in the Genome Browser View. The variants can be shown in track format or in table format. When holding the mouse over the detected variants in the Track List, a tooltip appears with information about the individual variants. You will have to zoom in on the variants to be able to see the detailed tooltip.
): Two from the Variant Caller: the Unfiltered Variants is output before the filtering steps, the Variants passing filters is the one used in the Genome Browser View (see
.
http://resources.qiagenbioinformatics.com/manuals/clcgenomicsworkbench/current/index.php?manual=_annotated_variant_table.html for a definition of the variant table content). The third is the Indels indirect evidence track produced by the Structural Variant Caller. This is also available in the Genome Browser View. The variants can be shown in track format or in table format. When holding the mouse over the detected variants in the Track List, a tooltip appears with information about the individual variants. You will have to zoom in on the variants to be able to see the detailed tooltip.
- Genome Browser View (
 ) A collection of tracks presented together. Shows the human reference sequence, genes, transcripts, coding regions, the mapped reads, the identified variants, and the indels indirect evidence variants (see figure 22.5).
) A collection of tracks presented together. Shows the human reference sequence, genes, transcripts, coding regions, the mapped reads, the identified variants, and the indels indirect evidence variants (see figure 22.5).
It is important that you do not delete any of the produced files individually as some of the outputs are linked to other outputs. If you would like to delete the outputs, please always delete all of them at the same time.
We recommend that you first inspect the target region coverage report to check that the majority of reads are mapping to the targeted region, and to see if the coverage is sufficient in regions of interest. Furthermore, check that at least 90% of reads are mapped to the human reference sequence.
Afterwards please open the Track List file (see 22.36).
The Genome Browser View includes the track of identified variants in context to the human reference sequence, genes, transcripts, coding regions, targeted regions and mapped sequencing reads.
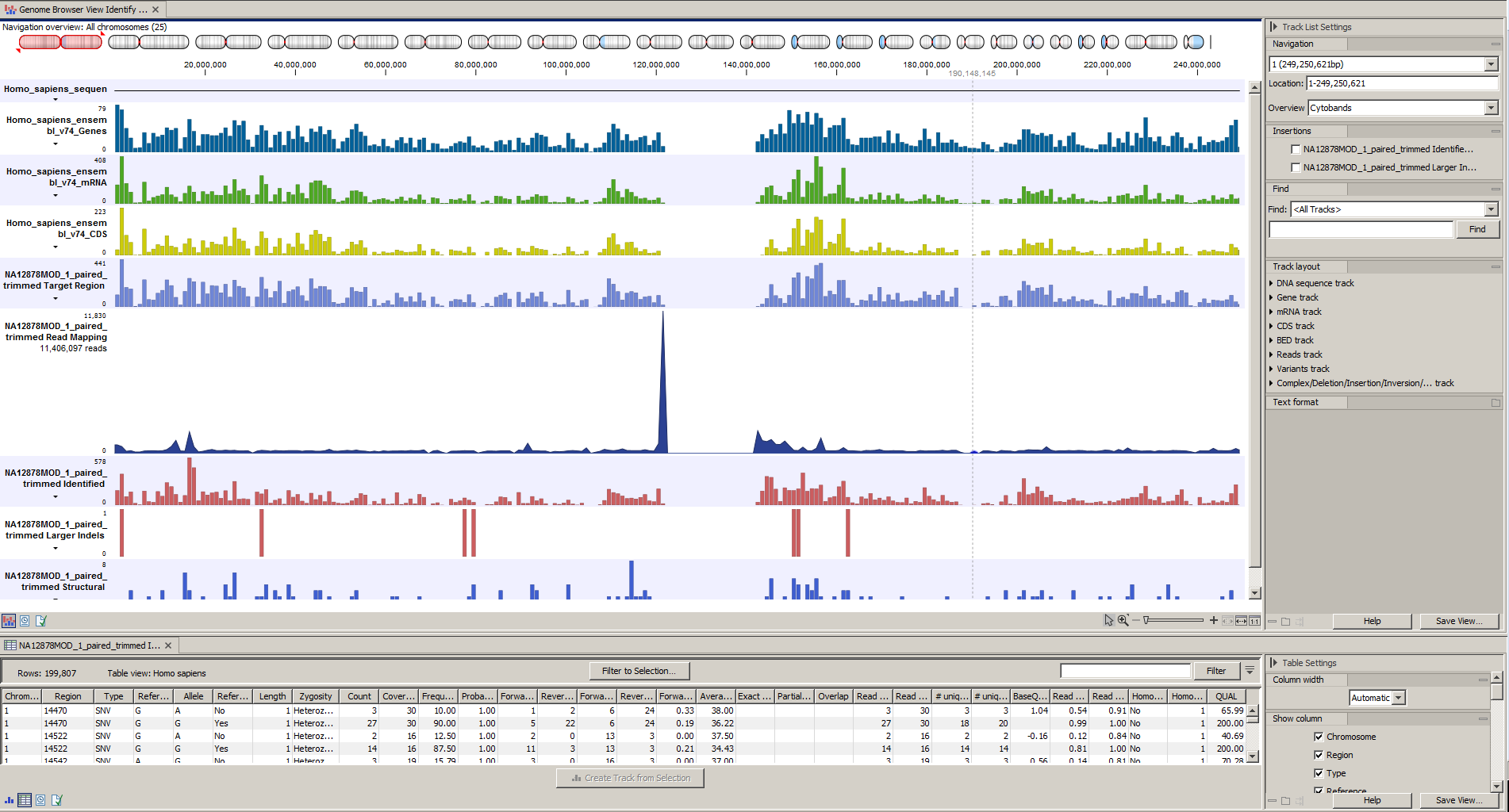
Figure 22.36: The Genome Browser View allows you to inspect the identified variants in the context of the human genome.
Open the variant track as a table to see information about all identified variants (see 22.37).
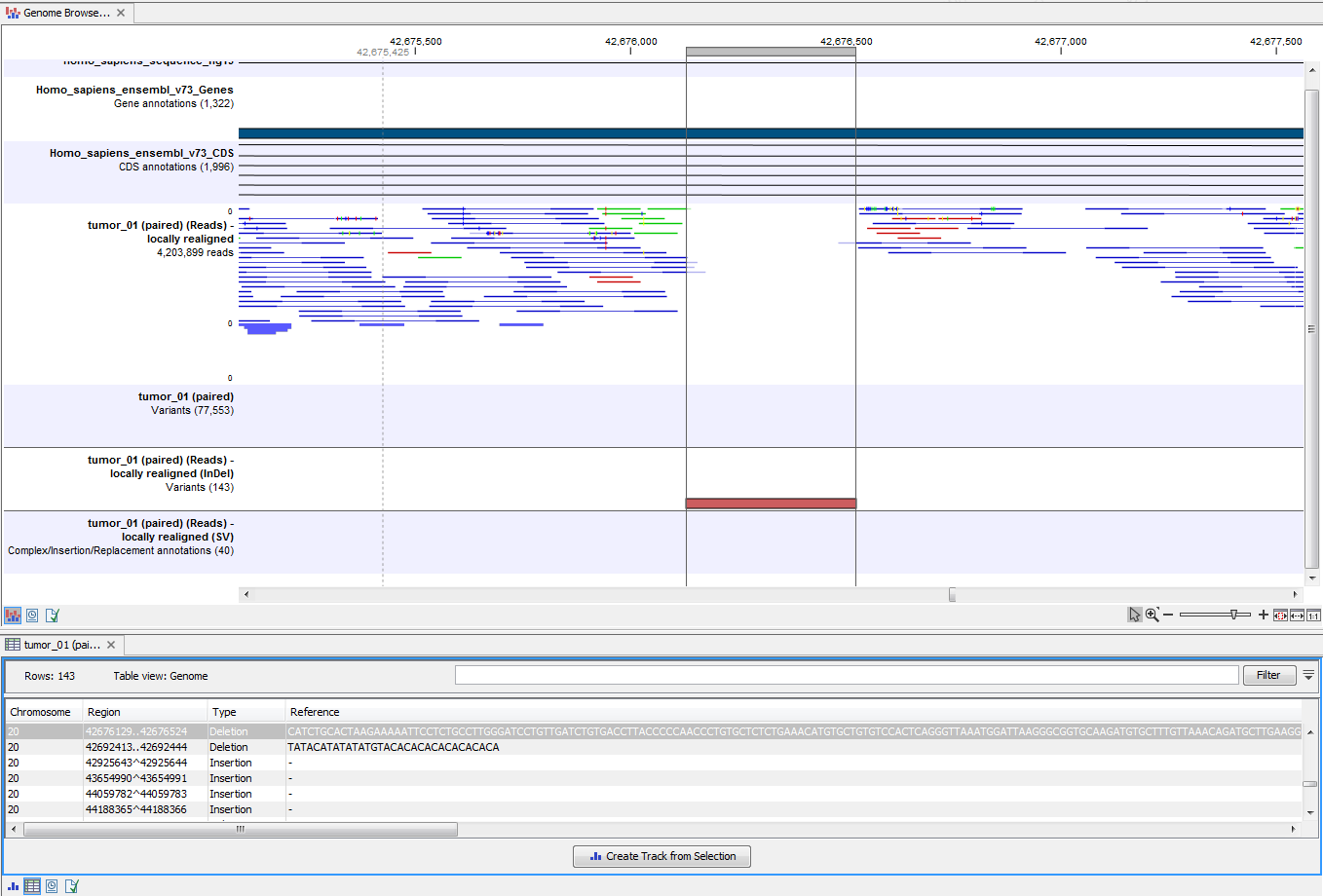
Figure 22.37: Genome Browser View with an open track table to inspect identified variants more closely in
the context of the human genome.