Identify QIAseq Exome Germline Variants
The Identify QIAseq Exome Germline Variants template workflow calls germline variants.
It can be found at:
Template Workflows | Biomedical Workflows (![]() ) | QIAseq Sample Analysis (
) | QIAseq Sample Analysis (![]() ) | QIAseq Analysis workflows (
) | QIAseq Analysis workflows (![]() ) | Identify QIAseq Exome Germline Variants (
) | Identify QIAseq Exome Germline Variants (![]() )
)
This workflow can also be launched from the Analyze QIAseq Samples guide, which is described in The Analyze QIAseq Samples guide. It is available under the Exome tab.
If you are connected to a CLC Server via your Workbench, you will be asked where you would like to run the analysis. We recommend that you run the analysis on a CLC Server when possible.
In the "Select Reads" wizard step, specify the data to be analyzed (figure 13.2). This workflow expects sequencing reads as input. When selecting data from the Navigation Area, these would normally be supplied as sequence lists.
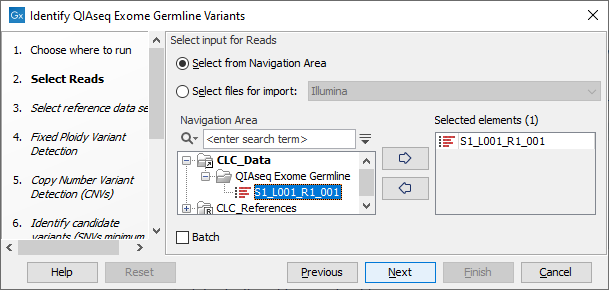
Figure 13.2: Select the data to analyze.
The following dialog helps you set up the relevant Reference Data Set. If you have not downloaded the Reference Data Set yet, the dialog will suggest the relevant data set and offer the opportunity to download it using the Download to Workbench button. (See figure 13.3).
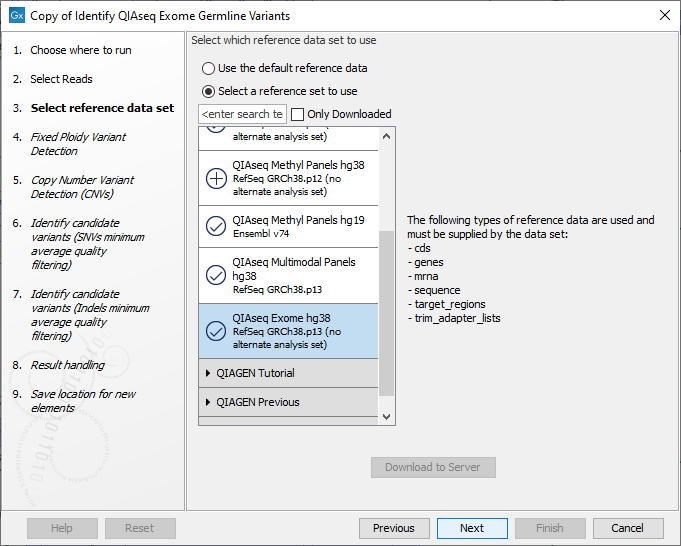
Figure 13.3: The relevant Reference Data Set is highlighted. To the right, the types of reference data needed by the workflow are listed.
Note that if you wish to Cancel or Resume the Download, you can close the template workflow and open the Reference Data Manager where the Cancel, Pause and Resume buttons are available.
If the Reference Data Set was previously downloaded, the option "Use the default reference data" is available and will ensure the relevant data set is used. You can always check the "Select a reference set to use" option to be able to specify another Reference Data Set than the one suggested.
In the Fixed Ploidy Variant Detection wizard step, the variant detection options can be configured (figure 13.4). These are:
- Minimum coverage: Only variants in regions covered by at least this many reads are called.
- Minimum count: Only variants that are present in at least this many reads are called.
- Minimum frequency: Only variants that are present at least at the specified frequency (calculated as 'count'/'coverage') are called.
- Remove pyro-error variants Enable this option for removing variants that fulfill the requirements set for:
- In homopolymer regions with minimum length Only variants in homopolymer regions of minimum this length will be removed
- With frequency below Only variants with frequency (reference and homopolymeric reads only) below this value will be removed.
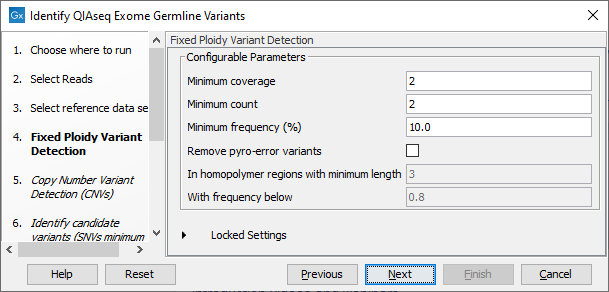
Figure 13.4: Specify the parameters for the Fixed Ploidy Variant Detection tool.
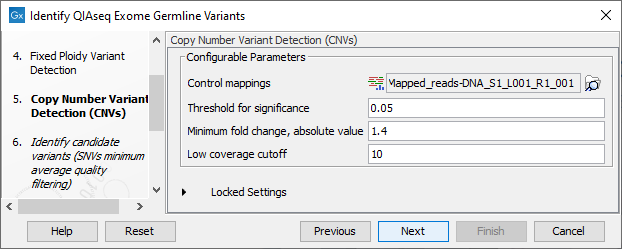
Figure 13.5: Specify the parameters for the Copy Number Variant Detection tool.
The dialog for Copy Number Variant Detection allows you to specify a control mapping against which the coverage pattern in your sample will be compared in order to call CNVs. If you do not specify a control mapping the Copy Number Variation analysis will not be carried out (figure 13.5).
Please note that if you want the copy number variation analysis to be done, it is important that the control mapping supplied is a meaningful control for the sample being analyzed. Mapping of control samples for the CNV analysis can be done using the workflow described in Create QIAseq Exome CNV Control Mapping.
A meaningful control must satisfy two conditions: (1) It must have a copy number status that is meaningful to compare against. For panels with targets on the X and Y chromosomes, the control and sample should be matched for gender. (2) The control read mapping must result from the same type of processing that will be applied to the sample.
In the next two dialogs individual filtering settings can be specified for SNVs and indels.
In the final wizard step, choose to Save the results of the workflow and specify a location in the Navigation Area before clicking Finish.
Subsections