Identify Known Variants in One Sample (WES)
The Identify Known Variants in One Sample (WES ready-to-use workflow combines data analysis and interpretation. It should be used to identify known variants as specified by the user (e.g., known breast cancer associated variants) for their presence or absence in a sample. This workflow will not identify new variants.
The workflow maps the sequencing reads to a human genome sequence and does a local realignment of the mapped reads to improve the subsequent variant detection. In the next step, only variants specified by the user are identified and annotated in the newly generated read mapping.
Before starting the workflow, you may need to import your the following files with the Import | Tracks tool (see http://resources.qiagenbioinformatics.com/manuals/clcgenomicsworkbench/current/index.php?manual=Import_tracks.html):
- Import your known variants. Variants can be imported in GVF or VCF format.
- Import your targeted regions. A file with the genomic regions targeted by the amplicon or hybridization kit can usually be provided by the vendor, either BED or GFF format.
Run the Identify Known Variants in One Sample (WES) workflow
- Go to the toolbox and double-click on
Ready-to-Use Workflows | Whole Exome Sequencing (
 ) | General Workflows (WES) (
) | General Workflows (WES) ( ) | Identify Known Variants from One Sample (WES) (
) | Identify Known Variants from One Sample (WES) ( )
)
- First select the reads of the sample that should be tested for presence or absence
of your known variants (figure 21.11).
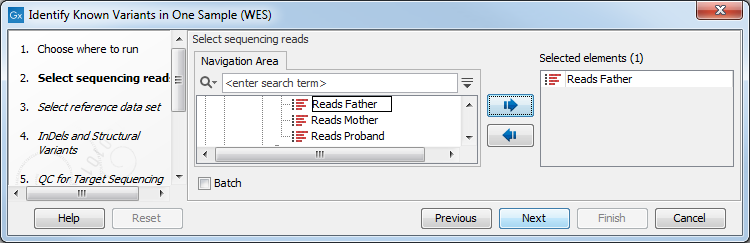
Figure 21.11: Select the sequencing reads from the sample you would like to test for your known variants.If several samples from different folders should be analyzed, the tool has to be run in batch mode. This is done by selecting "Batch" and specifying the folders that hold the data you wish to analyse.
- In the next wizard step, select the reference data set should be used to identify the known variants (figure 21.12).
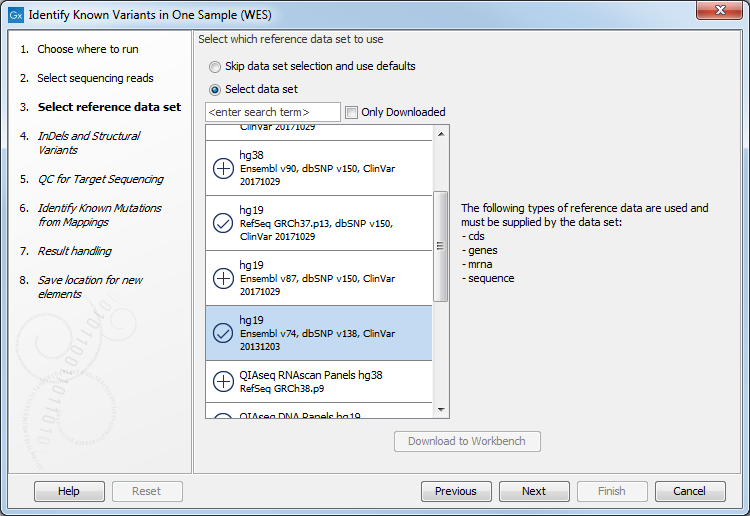
Figure 21.12: Choose the relevant reference Data Set to identify the known variants. - Specify the target region for the Indels and Structural Variants tool (figure 21.13). This step is optional and will speed the completion time of the workflow by running the tool only on the selected target regions. If you do not have a targeted region file to provide, simply click Next.
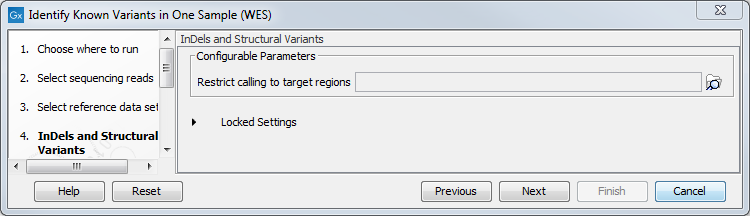
Figure 21.13: Specify the targeted region file for the Indels and Structural Variants tool. - Specify the parameters for the QC for Target Sequencing tool (figure 21.14).
When working with targeted data (WES or TAS data), quality checks for the targeted sequencing is included in the workflows. This step is not optional, and you need to specify the targeted regions file adapted to the sequencing technology you used. Choose to use the default settings or to adjust the parameters.
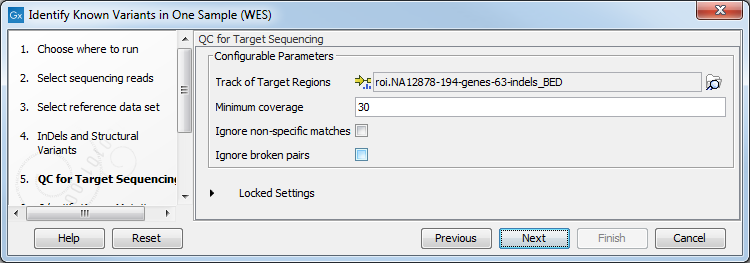
Figure 21.14: Specify the parameters for the QC for Target Sequencing tool.The parameters that can be set are:
- Minimum coverage provides the length of each target region that has at least this coverage.
- Ignore non-specific matches: reads that are non-specifically mapped will be ignored.
- Ignore broken pairs: reads that belong to broken pairs will be ignored.
- In the Identify Known Mutations form Mappings, select a variant track containing the known variants you want to identify in the sample (figure 21.15).
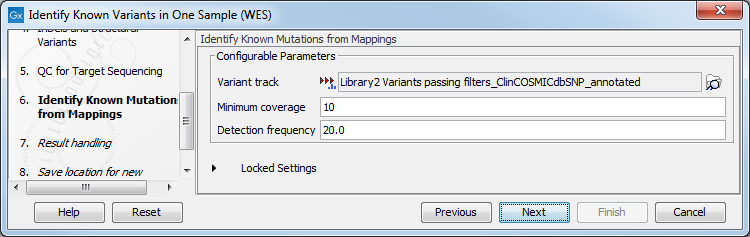
Figure 21.15: Specify the track with the known variants that should be identified.The parameters that can be set are:
- Minimum coverage The minimum number of reads that covers the position of the variant, which is required to set "Sufficient Coverage" to YES.
- Detection frequency The minimum allele frequency that is required to annotate a variant as being present in the sample. The same threshold will also be used to determine if a variant is homozygous or heterozygous. In case the most frequent alternative allele at the position of the considered variant has a frequency of less than this value, the zygosity of the considered variant will be reported as being homozygous.
The parameter "Detection Frequency" will be used in the calculation twice. First, it will report in the result if a variant has been detected (observed frequency > specified frequency) or not (observed frequency <= specified frequency). Moreover, it will determine if a variant should be labeled as heterozygous (frequency of another allele identified at a position of a variant in the alignment > specified frequency) or homozygous (frequency of all other alleles identified at a position of a variant in the alignment < specified frequency).
- In the last wizard step you can check the selected settings by clicking on the button labeled Preview All Parameters.
In the Preview All Parameters wizard you can only check the settings, and if you wish to make changes you have to use the Previous button from the wizard to edit parameters in the relevant windows.
- Choose to Save your results and click Finish.
Output from the Identify Known Variants in One Sample (WES)
The Identify Known Variants in One Sample (WES) tool produces five different output types:
- Read Mapping (
 ) The mapped sequencing reads. The reads are shown in different colors depending on their orientation, whether they are single reads or paired reads, and whether they map unambiguously (see http://resources.qiagenbioinformatics.com/manuals/clcgenomicsworkbench/current/index.php?manual=Coloring_mapped_reads.html).
) The mapped sequencing reads. The reads are shown in different colors depending on their orientation, whether they are single reads or paired reads, and whether they map unambiguously (see http://resources.qiagenbioinformatics.com/manuals/clcgenomicsworkbench/current/index.php?manual=Coloring_mapped_reads.html).
- Target Regions Coverage (
 ) A track showing the targeted regions. The table view provides information about the targeted regions such as target region length, coverage, regions without coverage, and GC content.
) A track showing the targeted regions. The table view provides information about the targeted regions such as target region length, coverage, regions without coverage, and GC content.
- Target Regions Coverage Report (
 ) The report consists of a number of tables and graphs that in different ways show e.g. the number, length, and coverage of the target regions and provides information about the read count per GC%.
) The report consists of a number of tables and graphs that in different ways show e.g. the number, length, and coverage of the target regions and provides information about the read count per GC%.
- Variants Detected in Detail (
 ) Annotation track showing the known variants. Like the "Overview Variants Detected" table, this table provides information about the known variants. Four columns starting with the sample name and followed by "Read Mapping coverage", "Read Mapping detection", "Read Mapping frequency", and "Read Mapping zygosity" provides the overview of whether or not the known variants have been detected in the sequencing reads, as well as detailed information about the Most Frequent Alternative Allele (labeled MFAA).
) Annotation track showing the known variants. Like the "Overview Variants Detected" table, this table provides information about the known variants. Four columns starting with the sample name and followed by "Read Mapping coverage", "Read Mapping detection", "Read Mapping frequency", and "Read Mapping zygosity" provides the overview of whether or not the known variants have been detected in the sequencing reads, as well as detailed information about the Most Frequent Alternative Allele (labeled MFAA).
- Track List Identify Known Variants (
 ) A collection of tracks presented together. Shows the annotated variant track together with the human reference sequence, genes, transcripts, coding regions, target regions coverage, the mapped reads, the overview of the detected variants, and the variants detected in detail.
) A collection of tracks presented together. Shows the annotated variant track together with the human reference sequence, genes, transcripts, coding regions, target regions coverage, the mapped reads, the overview of the detected variants, and the variants detected in detail.
It is a good idea to start looking at the Target Regions Coverage Report to see whether the coverage is sufficient in the regions of interest (e.g. > 30 ). Please also check that at least 90% of the reads are mapped to the human reference sequence. In case of a targeted experiment, we also recommend that you check that the majority of the reads are mapping to the targeted region.
When you have inspected the target regions coverage report you can open the Track List (see 21.16).
The Track List includes an overview track of the known variants and a detailed result track presented in the context of the human reference sequence, genes, transcripts, coding regions, targeted regions, and mapped sequencing reads.
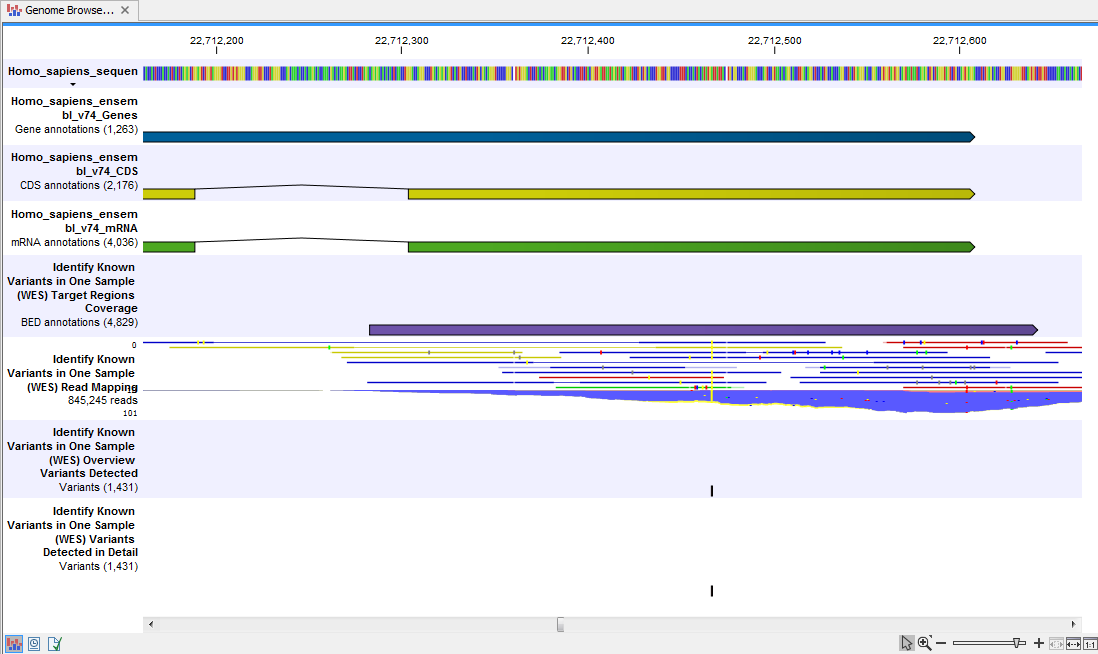
Figure 21.16: Track List that allows inspection of the identified variants in
the context of the human genome and external databases.
Finally, a track with conservation scores has been added to be able to see the level of nucleotide conservation (from a multiple alignment with many vertebrates) in the region around each variant.
Open the annotated variant as a table showing all variants and the added information/annotations (see 21.17).
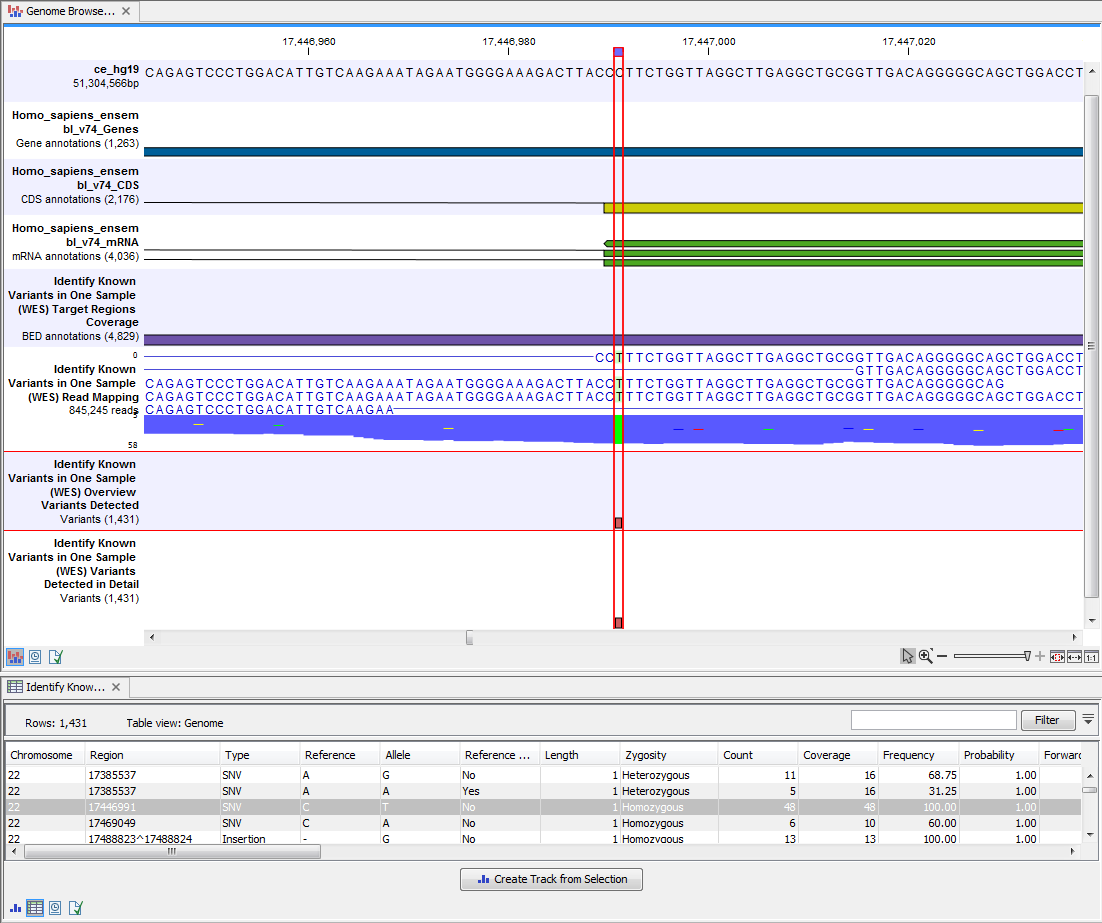
Figure 21.17: Track List with an open overview
variant track with information about if the variant has been detected or not,
the identified zygosity, if the coverage was sufficient at this position and
the observed allele frequency.
Note We do not recommend that any of the produced files are deleted individually as some of them are linked to other outputs. Please always delete all of them at the same time.