Control flow elements
Control flow elements control the flow of data through a workflow. They can be found in the Control Flow folder of the Add Element wizard, as shown in figure 12.34.
Figure 12.34: Control flow elements are found under the Control Flow folder in the Add Element wizard.
The control flow elements described in this section are:
- Iterate Used to define a branch of a workflow that should be run multiple times, by splitting its inputs into groups (iteration units, sometimes referred to as batch units).
- Collect and Distribute Used downstream of an Iterate element to collect all results of an iteration, and group them for collective analysis by further tools.
Branch on Coverage Specify how mapping data should be further processed based on coverage values in reports.
Further details about each element are provided below.
Note: Like other elements, control flow elements in a workflow can be renamed (see Basic configuration of workflow elements).
Iterate
Elements downstream of an Iteration element are run once for each input, or group of inputs, provided. The inputs to be included in a given iteration are referred to as "batch units" or "iteration units". Multiple Iterate elements can be included in a single workflow.
For workflows with containing a single Input element (green box) and a single Iterate element, batch units can be defined based on the location of the input data or based on a information in a metadata table. For any workflow containing multiple Iterate elements, or where there is a single Iterate element and the Batch button is checked when starting the workflow, batch units must be defined using information in a metadata table (Running workflows in batch mode).
Running a workflow with a single Iterate element at the top of a workflow, no downstream Collect and Distribute element (described in the next section), and a single Input element is equivalent to running a similar workflow design without the Iterate element in Batch mode. In this case, the simpler workflow design, without the Iterate element, is usually preferable. In both cases, batch units are set up as described in Batch processing.
Configuring an Iterate element
The configuration options available for an Iterate element are shown in figure 12.35. They are:
- Number of coupled inputs The number of separate inputs for each given iteration. These inputs are "coupled" in the sense that, for a given iteration, particular inputs are used together. For example, when sets of sample reads should be mapped in the same way, but each set should be mapped to a particular reference (figure 12.36).
- Error handling Specify what should happen if an error is encountered. The default is that the workflow should stop on any error. The alternative is to continue running the workflow if possible, potentially allowing later batches to be analyzed even if an earlier one fails.
- Metadata table columns If the workflow is always run with metadata tables that have the same column structure, then it can be useful to set the value of the column titles here, so the workflow wizard will preselect them. The column titles must be specified in the same order as shown in the worfklow wizard when running the workflow. Locking this parameter to a fixed value (i.e. not blank) will require the definition of batch units to be based on metadata. Locking this parameter to a blank value requires the definition of batch units to be based on the organization of input data (and not metadata).
- Primary input If the number of coupled inputs is two or more, then the primary input (used to define the batch units) can be configured using this parameter.
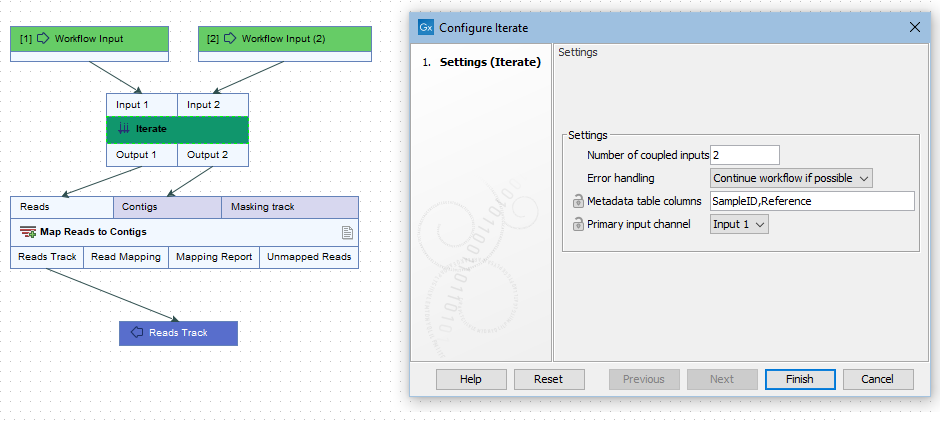
Figure 12.35: The number of coupled inputs in this simple example is 2, allowing each set of sample reads to be mapped to a paticular reference, rather than using the same reference for all iterations.
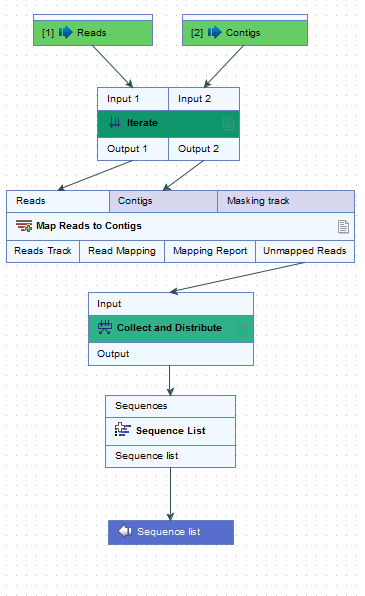
Figure 12.36: Reads can be mapped to specified contigs due to the 2 input channels of the Iterate element. Using this design, a single sequence list containing all the unmapped reads from all the initial inputs is generated. That would not be possible without the inclusion of the Iterate and Collect and Distribute elements.
Importing sequence data with sample information
A workflow containing just an Input, Output and Iterate element can be a useful tool to create a CLC Metadata Table with sample information and data elements associated with the relevant rows. This can then be used when launching tools and workflows requiring metadata. A template workflow with this design, Import with Metadata, is provided in the Preparing Raw Data template workflow folder in the Toolbox, and is described in Import with Metadata.
Collect and Distribute
Collect and Distribute elements are relevant in workflows with upstream Iterate elements. The steps between an Iterate element and a Collect and Distribute element are referred to as an "iteration block. When a Collect and Distribute element is encountered, intermediate results with that iteration block are collected. That data is passed to downstream elements according to configuration carried out when launching the workflow.
Configuring a Collect and Distribute element
By default, a Collect and Distribute element has one output channel. In this case, all results from the iteration block are collected and then passed on to downstream steps of the workflow.
More than one output channel can be configured by entering terms in a a comma separated list in the Outputs field (figure 12.37). The number of terms determines the number of output channels. Connections between these output channels and input channels of downstream elements determine how data should be distributed in the following stage of the workflow.
If the Collect and Distribute element has more than one output channel, the path taken by a given element is determined by the value in the metadata column specified when launching the workflow. This column can be preconfigured in the Group by metadata column setting.
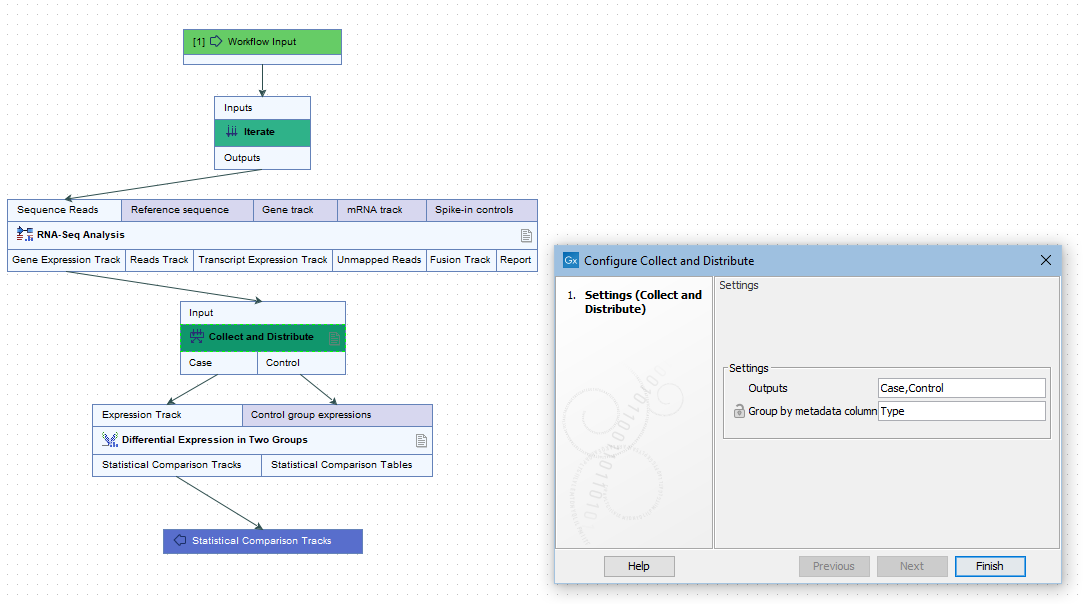
Figure 12.37: A comma separated list of terms in the Outputs field of the Collect and Distribute element defines the number of output channels and their names.
For example, when launching the workflow in figure 12.38, a metadata column called "Type" was specified for defining which samples were cases and which were controls. The iteration units were defined by the contents of the "ID" column (figure 12.39).
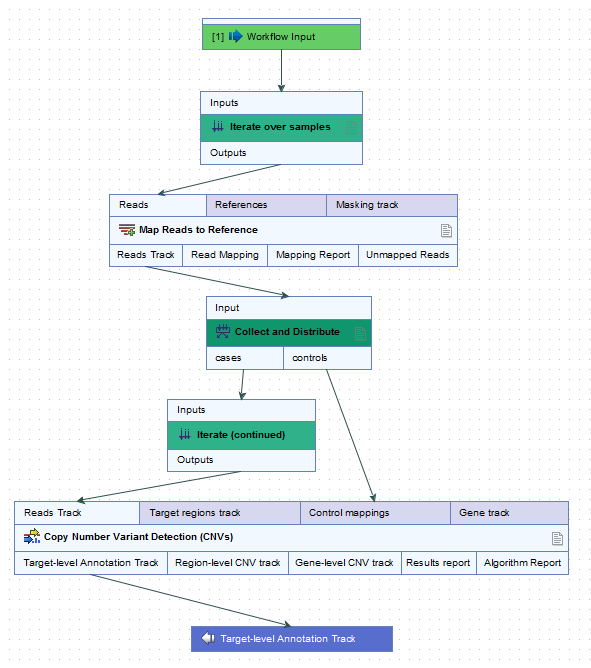
Figure 12.38: In this workflow, each case sample is analyzed against all of the control samples.
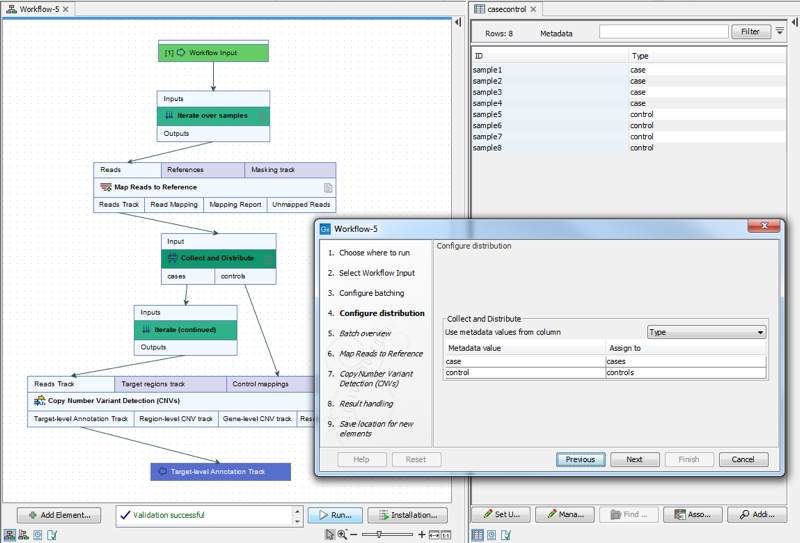
Figure 12.39: Contents of the metadata column "Type" define which samples are cases and which are controls. Iteration units are defined by the contents of thethe "ID" column.
Branch on Coverage
Branch on Coverage elements take a read mapping and a report as inputs. Each read mapping flows through Pass or the Fail output channel based on the coverage value in the corresponding report. In the example in figure 12.40, only mappings with coverage values in the corresponding report that meet the conditions specified in the Branch on Coverage element are passed to the downstream variant detection step.
Reports generated by the following tools are supported for use with Branch on Coverage elements:
- QC for Targeted Sequencing
- QC for Read Mapping Note: Zero coverage regions from these reports are ignored.
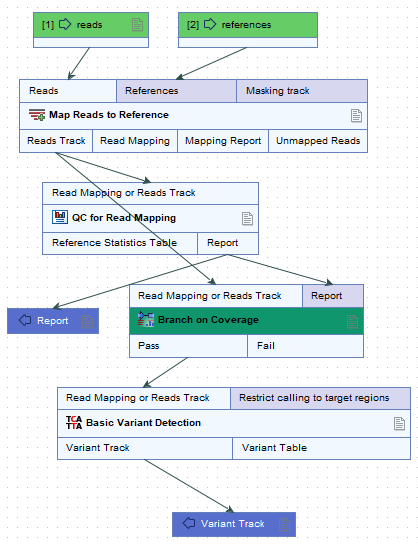
Figure 12.40: A read mapping and a report flow into the Branch on Coverage element. Mappings with adequate coverage, according to the value in the corresponding report, flow through the Pass output channel and are procssed further. The others flow through the Fail channel. In this workflow, those mappings are not processed further.
The type of value (Minimum, Median, Average, Maximum), the comparison to make (>=, =, <=), and a numerical value define the coverage required for a mapping to flow through the Pass channel (figure 12.41) .
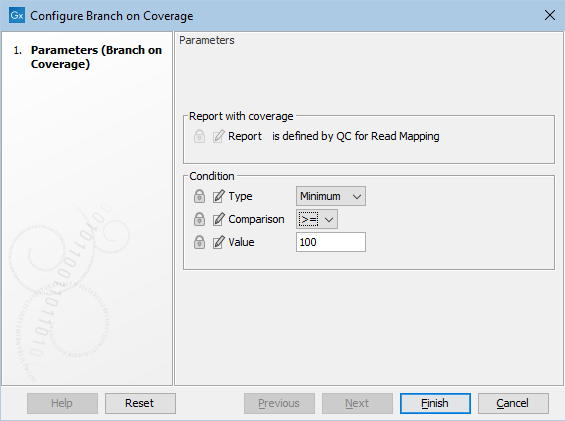
Figure 12.41: Configuration of a Branch on Coverage element.