Paired data
For paired data, the assumption is made that if both parts of the pair share the same sequence, they are duplicates, and only one copy of the pair is left in the output. Figure 8.3 shows an example of a paired read duplicate.
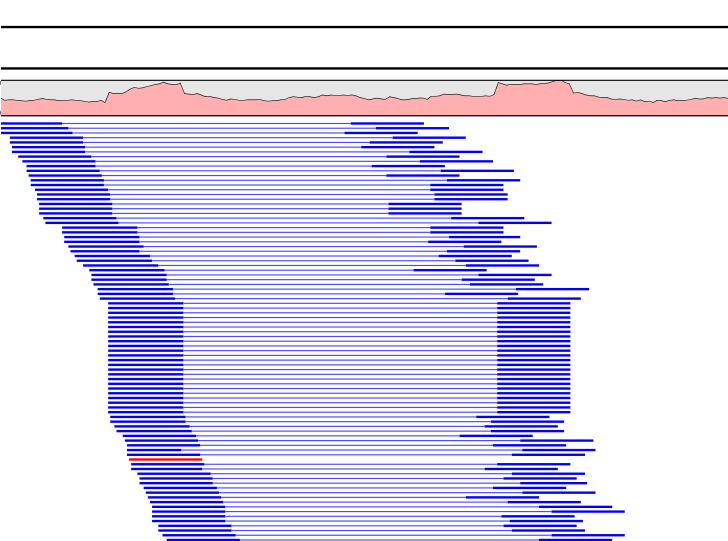
Figure 8.24: Paired reads with identical starting positions.
The algorithm also takes sequencing errors into account when filtering out paired data.