Selective download of results
Individual results can be downloaded using the Workflow Result Metadata table, which is generated for each batch. This is particularly useful when the amount of data generated by a workflow execution is so large that it is not practical to download all the results at once.
In the Cloud Job Search table, download the Workflow Result Metadata table for selected jobs by clicking on the Download Metadata button.
In a Workflow Result Metadata table, each workflow output is shown in a separate row. The path to the output in the AWS S3 location is indicated in the column titled "External path", as shown in figure 7.6. When one or more rows in the table are selected, the Find Associated Data button is enabled. Clicking on this button opens a new table, where the external references (not yet downloaded) are listed, as well as any results already downloaded into the Navigation Area.
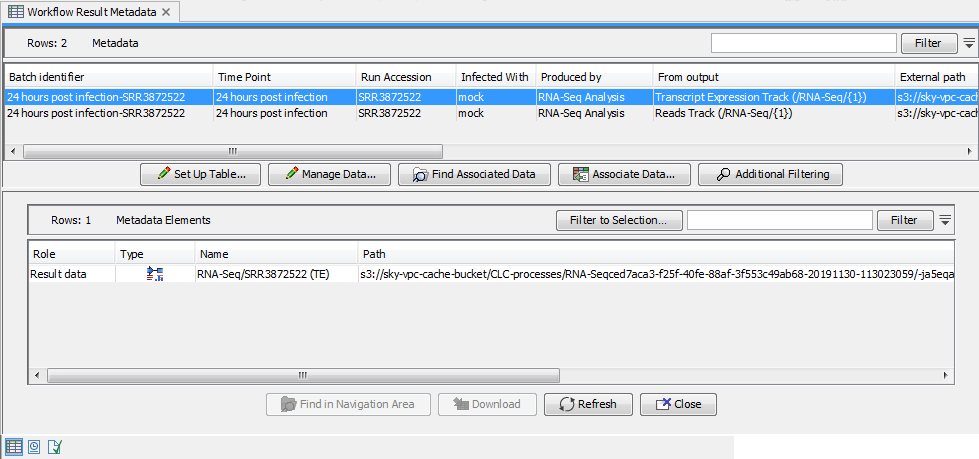
Figure 7.19: The "External path" column in the Workflow Result Metadata table shows the path to the result in AWS S3. After the "Find Associated Data" button is clicked, a Metadata Elements table which lists associated data elements and their locations. Here one element is local, and one is in the cloud.
To download particular data elements from the cloud, select the desired rows in the Metadata Elements table, and click on the Download button. Data elements downloaded are placed in the subfolder (if any) that was specified by the workflow design for the given output. New folders are created as required. Therefore, we recommend selecting the same folder to store different results for the same workflow. This ensures that the outputs are organized in the same folder structure that they would have been if the workflow had been executed by the CLC Workbench.
When an data element is downloaded, it is automatically associated with the relevant row of the Workflow Result Metadata table, and can be found by clicking on the Find Associated Data button again (figure 7.7). External references will not be removed from the Workflow Result Metadata table by downloading a result. Results can be downloaded this way any number of times.
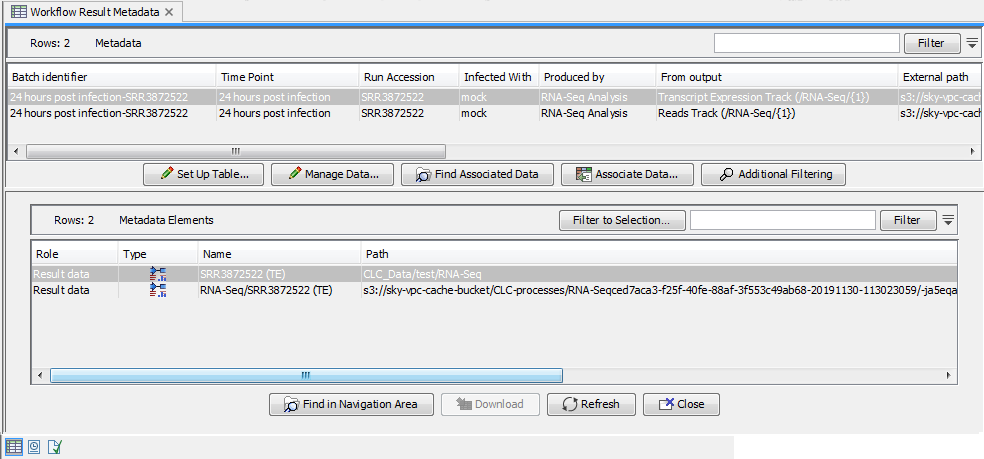
Figure 7.20: When the results have been downloaded, they are automatically associated with the relevant row of the Workflow Result Metadata table, and can be located by pressing the "Find Associated Data" button again.
A connection to the CLC Genomics Cloud Engine is required to find the Workflow Result Metadata table and download it using the Cloud Job Search functionality. However, only the AWS S3 connection is required for downloading results via the Workflow Result Metadata table.
Thus, by saving the Workflow Result Metadata table, you can download the results from AWS S3 at a later point, as long as the data is still available in AWS S3. You do not need a connection to the CLC Genomics Cloud Engine or to use the Cloud Job Search for this activity.
Note: Exported data cannot be downloaded selectively. To download data exported by the workflow, you must use the Download All Results button in the Cloud Job Search tool. See section Downloading all results for further details.