The Identify QIAseq DNA Variants ready-to-use workflows
There are four Identify QIAseq DNA Variants ready-to-use workflows, each optimized to work with either somatic or germline application, from Illumina or Ion Torrent reads.
Somatic/germline specificity: For somatic variant detection, the ready-to-use workflow uses the Low Frequency Variant Detection tool, a variant caller that does not base its statistical model on a bi-allelic assumption. This variant caller will thus declare a site heterozygous if it detects more than one allele at that site, even if one of the alleles is detected at very low frequency and later filtered out. For germline applications, the workflows use the Fixed Ploidy Variant Detection tool. This variant caller has higher precision than the Low frequency Variant Detection tool, particularly at low to moderate levels of coverage (< 30x). At high levels of coverage (>100x) the Fixed Ploidy Variant Detection tool will exhibit low sensitivity for variants with allele frequencies far from what is expected for germline variants (that is 50 or 100%).
Illumina/Ion Torrent specificity: Among various differences in the filtering strategy applied in the workflows aimed at analysing data from a particular sequencing technology, the workflow for Ion Torrent data includes an extra step that removes non SNV type variants that are likely due to artifacts.
In each case, the parameter values applied as defaults have been optimized for high sensitivity and specificity when detecting variants.
All workflows use the same Reference Data Set: before starting any one of the workflows, open the Reference Data Manager, select QIAseq DNA Panels hg19, Download the set if you have not done so before and close the References Management window.
The Identify QIAseq DNA Variants ready-to-use workflow can be found here:
Ready-to-Use Workflows | QIAseq Panel Analysis (![]() ) | QIAseq Analysis workflows (
) | QIAseq Analysis workflows (![]() ) | Identify QIAseq DNA (Somatic/Germline) Variants (Illumina/Ion Torrent) (
) | Identify QIAseq DNA (Somatic/Germline) Variants (Illumina/Ion Torrent) (![]() )
)
Double-click on the Identify QIAseq DNA Variants ready-to-use workflow relevant for your samples to run the analysis.
If you are connected to a CLC Server via your Workbench, you will be asked where you would like to run the analysis. We recommend that you run the analysis on a CLC Server when possible. Click Next.
In the Select reads dialog, specify the sequencing reads that should be analyzed (figure 5.1).
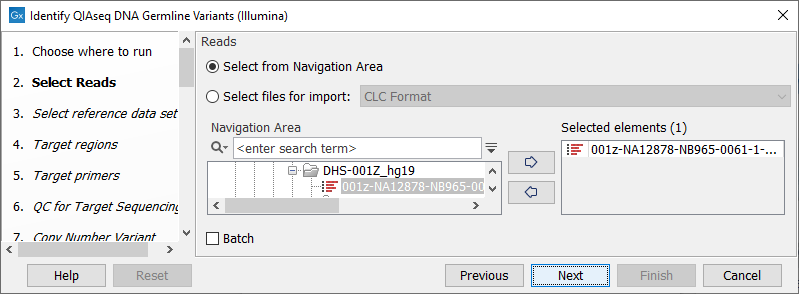
Figure 5.1: Select the sequencing reads by double-clicking on the file name or by clicking once on the file name and then on the arrow pointing to the right hand side.
The following dialog helps you set up the relevant Reference Data Set. If you have not downloaded the Reference Data Set yet, the dialog will suggest the relevant data set and offer the opportunity to download it using the Download to Workbench button. (figure 5.2).
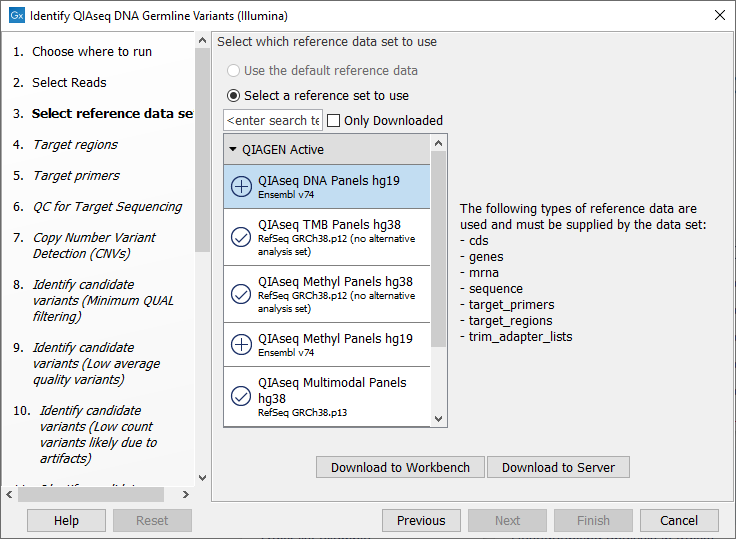
Figure 5.2: The relevant Reference Data Set is highlighted; in the text to the right, the types of reference needed by the workflow are listed.
Note that if you wish to Cancel or Resume the Download, you can close the ready to use workflow and open the Reference Data Manager where the Cancel, Pause and Resume buttons are available.
If the Reference Data Set was previously downloaded, the option "Use the default reference data" is available and will ensure the relevant data set is used. You can always check the "Select a reference set to use" option to be able to specify another Reference Data Set than the one suggested.
In the next dialog (figure 5.3), specify the relevant target region from the drop down list.
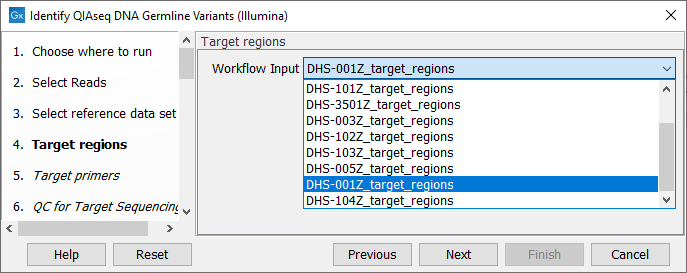
Figure 5.3: Select the target regions file specific to the panel used.
In the next dialog (figure 5.4), specify the relevant target primer from the drop down list.
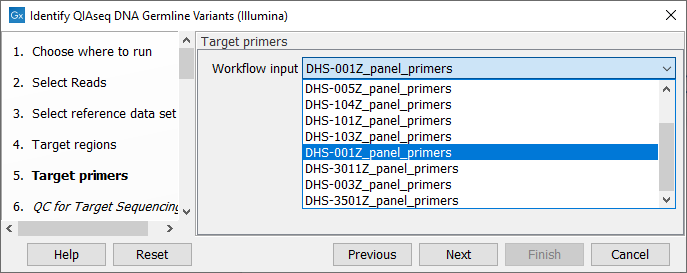
Figure 5.4: Select the target primer file specific to the panel used.
In the dialog called QC for Target Sequencing, you can modify the Minimum coverage needed on all positions in a target for this target to be considered covered (figure 5.5). Note that the default value for this tool depends on the application chosen (somatic or germline).
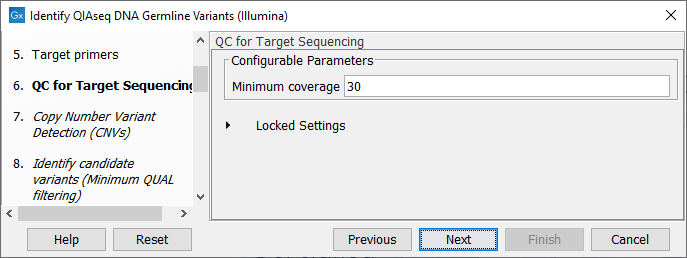
Figure 5.5: Setting the Minimum coverage parameter of the QC for Target Sequencing.
The dialog for Copy Number Variant Detection allows you to specify a control mapping against which the coverage pattern in your sample will be compared in order to call CNVs. If you do not specify a control mapping, or if the target region files contains fewer than 50 regions, the Copy Number Variation analysis will not be carried out.
Please note that if you want the copy number variation analysis to be done, it is important that the control mapping supplied is a meaningful control for the sample being analyzed. Mapping of control samples for the CNV analysis can be done using the workflow described in Create QIAseq DNA CNV Control Mapping workflows.
A meaningful control must satisfy two conditions: (1) It must have a copy number status that it is meaningful for you to compare your sample against. For panels with targets on the X and Y chromosomes, the control and sample should be matched for gender. (2) The control read mapping must result from the same type of processing that will be applied to the sample. One way to achieve this is to process the control using the workflow (without providing a control mapping for the CNV detection component) and then to use the resulting UMI reads track as the control in subsequent workflow runs.
If you have previously run the workflow with control data, you will find the mapping in the Reports and Data folder (Mapped UMI Reads).
The parameters for variant detection are not adjustable and have been set to generate an initial pool of all potential variants. These are then passed through a series of filters to remove variants that are suspected artifacts. Variants failing to meet the (adjustable) thresholds for quality, read direction bias, location (low frequency indels within homopolymer stretches), frequency or coverage would not be included in the filtered output.
Some filters only remove alternative alleles - and not reference alleles - as this potentially leads to wrong interpretation of variants by the VCF exporter where such variants could be misinterpreted as hemizygote when the reference allele is missing.
Note that each filter has been configured with specific default values depending on the technology (Illumina / Ion Torrent) and application (somatic or germline) chosen to provide the best sensitivity and precision in the variants output by each workflow. However, benchmarking was performed on samples of relatively high coverage. Therefore, additional filtering might be needed, or filtering values adjusted when working with low coverage samples. This can only be done by running the workflows listed in the Toolbox, and not by using the panel guide. When configuring filters, do not load any annotations, nor try to change the name of the filters in the first column, as it would disable the filter completely.
Finally, in the last wizard step, choose to Save the results of the workflow and specify a location in the Navigation Area before clicking Finish.
Note that reads that span the origin of the MT chromosome are not trimmed by the Trim Primers of Mapped Reads tool when running the Identify QIAseq DNA Variants ready-to-use workflows on data from the DHS-105Z panel.
Subsections
- Identify QIAseq DNA Somatic Variants with FLT3 Identification ready-to-use workflow
- Output from the Identify QIAseq DNA Variants workflow
- Quality Control for the Identify QIAseq DNA Variants workflow