Result of hypergeometric tests on annotations
The result of performing hypergeometric tests on annotations using GO biological process is shown in figure 27.99.
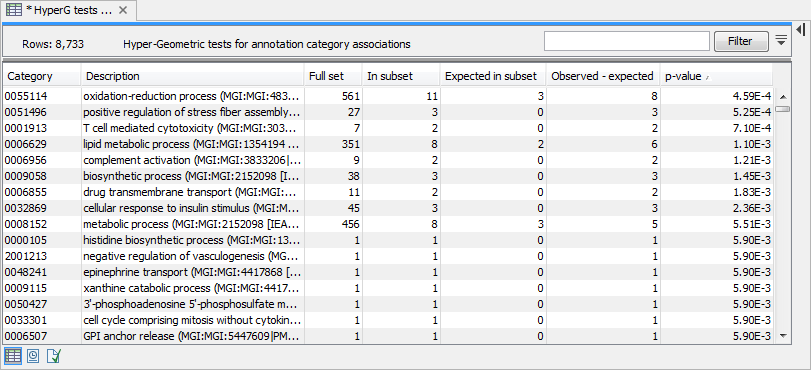
Figure 27.99: The result of testing on GO biological process.
The table shows the following information:
- Category. This is the identifier for the category.
- Description. This is the description belonging to the category. Both of these are simply extracted from the annotations.
- Full set. The number of features in the original experiment (not the subset) with this category. (Note that this is after removal of duplicates).
- In subset. The number of features in the subset with this category. (Note that this is after removal of duplicates).
- Expected in subset. The number of features we would have expected to find with this annotation category in the subset, if the subset was a random draw from the full set.
- Observed - expected. 'In subset' - 'Expected in subset'
- p-value. The tail probability of the hyper geometric distribution This is the value used for sorting the table.
Categories with small p-values are over-represented on the features in the subset relative to the full set.