Job Distribution
The CLC Genomics Server has the concept of distributing jobs to nodes. This means that you can have a master server with the primary purpose of handling user access, serving data to users and starting jobs, and you have a number of nodes that will execute these jobs.
Two main models of this setup are available: a master server that submits tasks to dedicated execution nodes, and a master server that submits tasks to a local grid system. Figure 6.1 shows a schematic overview of these possibilities, and they are described in text below.
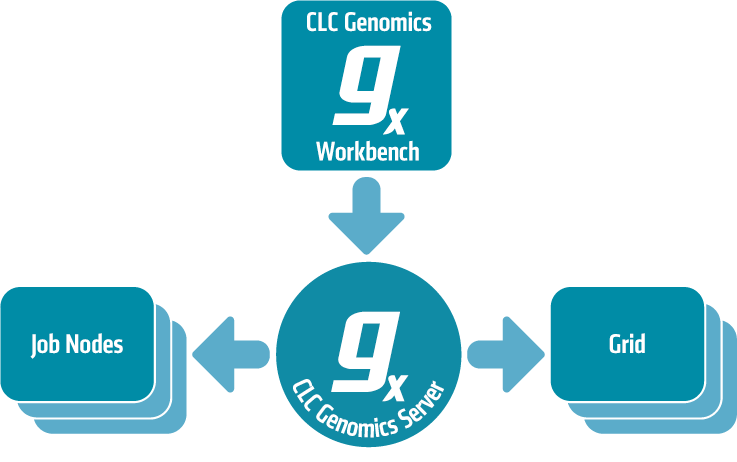
Figure 6.9: An overview of the job distribution possibilities.
- Model I: Master server with execution nodes - here, a master server submits CLC jobs directly to machines running the CLC Genomics Server for execution. In this setup, a group of machines (from two upwards) have the CLC Genomics Server software installed on them. The system administrator assigns one of them as the master node. This node controls the distribution of jobs. The other nodes are execution nodes, which carry out the computational tasks they are assigned. The execution nodes wait for the master node to assign them a job, and once the job is executed, they are available for the next job. With this set-up, the CLC master server controls the queue and the distribution of compute resources. This has the advantage of being simple to set up and maintain, with no other software required. However, it is not well suited to situations where the compute resources are shared with other systems because there is no mechanism for managing the load on the computer. This setup works best when the execute nodes are machines dedicated to running a CLC Genomics Server. Further details about this setup can be found in Setting up exection nodes
- Model II: Master server submitting to grid nodes - here the master server submits jobs to a third party job scheduler. That scheduler controls the resources on a local computer cluster (grid) where the job will be executed. This means that it is the responsibility of the native grid job scheduling system to start the job. When the job is started on one of the grid nodes, a CLC Grid Worker, which is a stand-alone executable including all the algorithms on the server, is started with a set of parameters specified by the user. Further details about this setup can be found in Setting up grid integration.
Subsections