Running workflows in the cloud
To run workflows in the cloud using the CLC Genomics Cloud Engine, select "CLC Genomics Cloud Engine" in the first step when launching a workflow (see figure 5.1).
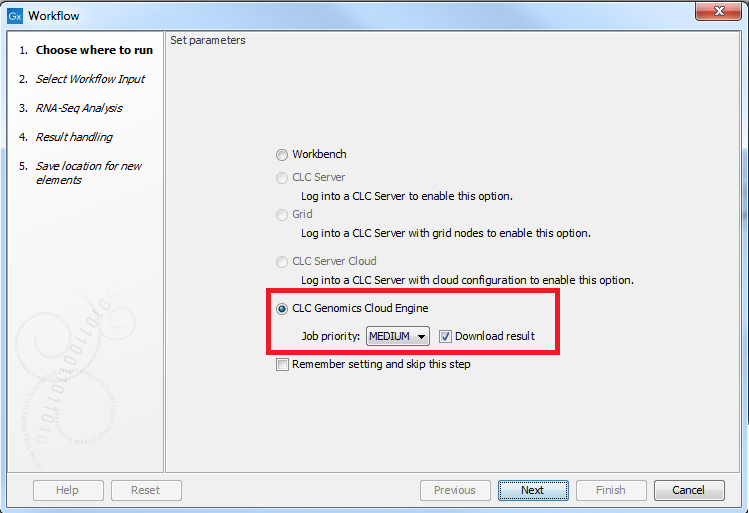
Figure 5.8: Select "CLC Genomics Cloud Engine" to run a workflow in the cloud.
Job priority and downloading results
The "Job priority" setting affects how quickly a job will be scheduled for execution:
- ASAP: The highest priority level. These jobs are always executed first.
- HIGH: The job will be placed in the priority queue with 60% probability.
- MEDIUM: The job will be placed in the priority queue with 30% probability.
- LOW: The job will be placed in the priority queue with 10% probability.
Select the Download result checkbox to download all results when the workflow is finished. Note that when analyzing large datasets, it may be desirable to leave this box unchecked. Results can be downloaded at a later time, including selective download of individual results, using the Cloud Job Search functionality, described in Cloud Job Search.
Data inputs and outputs
Locally available data and data already in the cloud can be used as input to workflows run in the cloud. The following data sources are available when launching a workflow:
- Elements from the Navigation Area Choose "Select from Navigation Area". The selected data will be uploaded to the AWS S3 cache bucket configured in the Settings for CLC Genomics Cloud Engine. If a given data element is already present in the cache bucket, as determined by the CLC URL of the data element and the time of its latest modification, then it will not be uploaded.
- Locally available data to be imported on the fly when the workflow is run Choose "Select files for import", and select the "Browse locally" button. The data will be uploaded to the AWS S3 cache bucket. If a file is already present in the cache bucket, as determined by the full path of the file and the time of its latest modification, then it will not be uploaded.
- Data in the cloud, to be imported on the fly when running the workflow in the cloud Choose "Select files for import", and select the "Browse data in the cloud" button (
 ). The analysis is carried out directly on the data in the cloud. It is not transferred to the CLC Workbench.
). The analysis is carried out directly on the data in the cloud. It is not transferred to the CLC Workbench.
In the Result handling step of the workflow wizard, the details of any data to be uploaded will be displayed, as shown in figure 5.2. If any of the data is already present in the cloud cache, and therefore will not be uploaded, this will also be indicated.
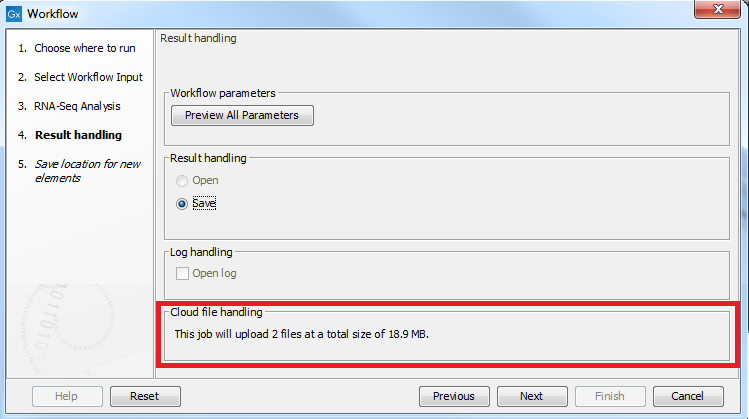
Figure 5.9: The data to be uploaded to the cloud is shown in the Result handling step of the workflow wizard.
In the last step of the wizard, a location must be selected for the outputs, even if the "Download result" checkbox was not checked in the first configuration step. This location is used to save log files to under some circumstances, for example, if a workflow run fails for particular reasons.
Following the progress of workflow jobs on the cloud
Each workflow submitted to the cloud is submitted as a batch consisting of jobs. A batch may consist of just a single job. Multiple jobs are included in a batch when:
- The "Batch" checkbox is selected when submitting the workflow, and/or
- The workflow design includes control flow elements, as described in the CLC Genomics Workbench manual: http://resources.qiagenbioinformatics.com/manuals/clcgenomicsworkbench/current/index.php?manual=Advanced_workflow_batching.html.
Each job within a batch is executed as a separate job in the cloud, potentially in parallel on separate server instances.
You can follow the progress of the workflow in the Processes area of the CLC Workbench (see figure 5.3). The icon next to the process indicates the status of the job submission:
-
 This icon indicates that data is being transferred to the cloud. Do not close your computer or disconnect from the cloud when this icon is displayed.
This icon indicates that data is being transferred to the cloud. Do not close your computer or disconnect from the cloud when this icon is displayed.
-
 This icon indicates the job submission is complete, including any data transfer. You can now close your computer or disconnect from the cloud if you wish.
This icon indicates the job submission is complete, including any data transfer. You can now close your computer or disconnect from the cloud if you wish.

Figure 5.10: The icon next to the cloud process in the Processes area indicates when the data upload is complete.
When the job submission is complete, right-clicking the arrow next to a process and selecting "Show in Cloud Job Search" will open the batch in the Cloud Job Search (see figure 5.4). This is described in more detail in Cloud Job Search.
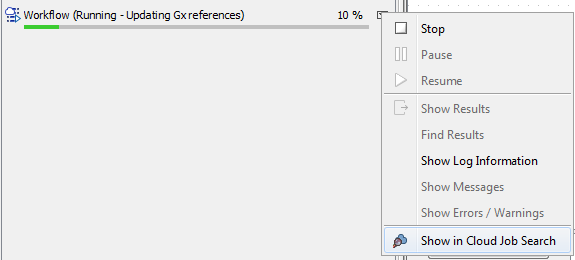
Figure 5.11: You can open an individiual job in the Cloud Job Search by right-clicking the arrow next to a process in the Processes area. This option is only available when the job submission to the cloud is complete, including any data transfer.
Note: If the "Download result" checkbox was selected in the first configuration step, and you close your laptop without exiting the CLC Workbench, then the results will be downloaded when you open the laptop again, once the execution has completed. However, if you exit the CLC Workbench, then the results will not be downloaded automatically from the cloud when you start the CLC Workbench again, even if the "Download result" checkbox had been selected. Results can always be found in the Cloud Job Search, as described in Cloud Job Search.