Prerequisites
Requirements for importing and exporting data to Amazon S3
To import data from and export data to Amazon S3, you need:
- An Amazon Web Services (AWS) account.
- An AWS Identity and Access Management (IAM) user with credentials for programmatic access (access key ID, secret access key). Such a user can be set up for an AWS account in the AWS Management Console: Services
 IAM
Users
Add User. Programmatic access should be granted to the user when setting the AWS access type (figure 1.1). Please note that the IAM user must only have access to the S3 locations where GCE, the CLC Genomics Server, and the CLC Workbench should be able to access files. The IAM user should for example not have API access to anything else in AWS.
IAM
Users
Add User. Programmatic access should be granted to the user when setting the AWS access type (figure 1.1). Please note that the IAM user must only have access to the S3 locations where GCE, the CLC Genomics Server, and the CLC Workbench should be able to access files. The IAM user should for example not have API access to anything else in AWS.
- The IAM User should be granted the following permission policy: AmazonS3FullAccess. A more limiting policy can be used if there is a need to restrict access to Amazon S3 to some degree.
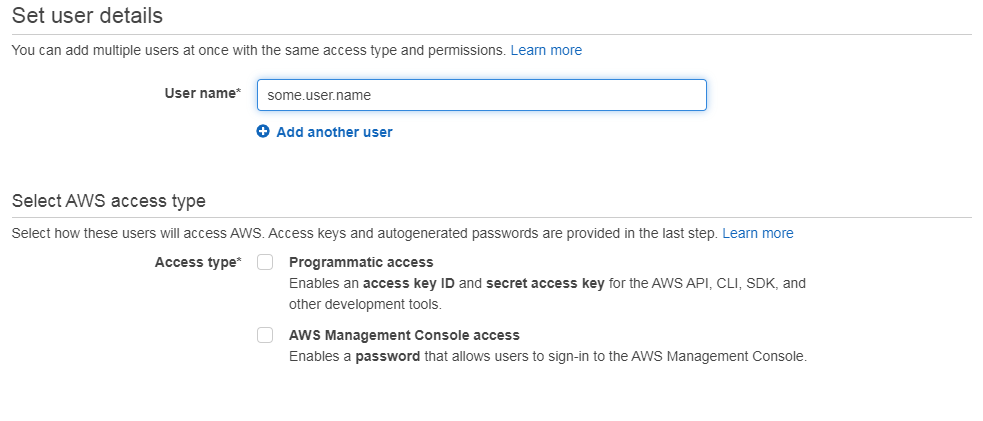
Figure 1.1: Enabling programmatic access for an AWS IAM user can be done in the AWS Management Console. Note: This screenshot is for illustration purposes only. Details may be changed at any time by AWS.
Requirements for running workflows and accessing results
In addition to the requirements above, you will need the following to be able to run workflows in the cloud, to find jobs or to download results from jobs that have been run in the cloud:
- The CLC Genomics Cloud Engine deployed on your AWS account. Read more about the product and request a quote here: https://www.qiagenbioinformatics.com/products/clc-genomics-cloud-engine/.
- At least one Amazon S3 bucket set up to be used for caching uploaded files. The CLC Genomics Cloud Engine includes a tool to set up such a bucket.
- The following permission policy granted to the IAM User: AWSResourceGroupsReadOnlyAccess. This policy grants the user the rights needed to automatically find the cache bucket in Amazon S3.