Import Cell Clusters
The Import Cell Clusters tool can import clusters for each cell. The importer produces Cell Clusters (![]() ) that can be used to define groups of cells for use in many tools such as Differential Expression for Single Cell. Cell Clusters can also be visualized in a Dimensionality Reduction Plot.
) that can be used to define groups of cells for use in many tools such as Differential Expression for Single Cell. Cell Clusters can also be visualized in a Dimensionality Reduction Plot.
Often the same file can be imported as either Cell Clusters or Cell Annotations. The principal advantage of Cell Clusters is that they can be edited within the Dimensionality Reduction Plot.
The importer can be found here:
Import (![]() ) | Import Cell Clusters (
) | Import Cell Clusters (![]() ).
).
The following options are available:
- Data file a single file in .csv or .xlsx format. The first row in the file is used as the name of the columns of the imported table. Each subsequent row in the file should describe a cell (though empty lines are ignored). Cells are identified by a combination of their barcode e.g. "AAGCT" and their sample id. The first column in the file will be treated as the sample id, and the second column will be treated as the barcode. Subsequent columns are different clusterings of the cells (see figure 2.5). When an Expression Matrix is supplied, the sample id column may be omitted.
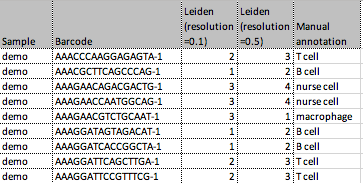
Figure 2.1: An example of a file that could be imported with Import Cell Clusters. The file contains three different clusterings. - Expression Matrix (optional when First column defines sample is selected). When an Expression Matrix is supplied:
- The sample id is taken from the matrix. If the file provides different sample ids than the matrix, then the importer fails with an error. This can be useful when checking that the file being imported matches the supplied matrix.
- Rows in the file describing cells that are not in the matrix are skipped.
- First column defines sample When this is enabled, there is no need to supply an Expression Matrix. However, the data file must have the sample id in the first column.
- Map clusters to QIAGEN Cell Ontology When this is enabled, each annotation will be translated to the QIAGEN Cell Ontology. The translation works by looking for known synonyms for each cell type in the ontology. For example, `Sertoli cells' are also called `nurse cells'. If the data file annotates cells as `nurse cells', and this option is selected, then in the imported file, the cells will be called `Sertoli cells' (see figure 2.6). This option can be useful when standardizing cell annotations from different sources. It is especially recommended if the imported data will be used to extend a QIAGEN Cell Type Classifier using the Train Cell Type Classifier tool.

Figure 2.2: The result of importing the file shown in figure 2.5 using the option `Map clusters to QIAGEN Cell Ontology'. Note that all the cell types have been translated to terms in the QIAGEN Cell Ontology. For example, `T cells' have been standardized to `T lymphocytes', and `nurse cells' have been standardized to `Sertoli cells'.