Accessing files on, and writing to, areas of the server filesystem
There are circumstances when it is beneficial to be able to interact with (non-CLC) files directly on your server filesystem. A common circumstance would be importing high-throughput sequencing data from folders where it is stored on the same system that your CLC Genomics Server is running on. This could eliminate the need for each user to copy large sequence data files to the machine their CLC Workbench is running on before importing the data into a CLC Genomics Server CLC server data area. Another example is if you wish to export data from CLC format to other formats and save those files on your server machine's filesystem (as opposed to saving the files in the system your Workbench is running on).
From the administrator's point of view, this is about configuring folders that are safe for the CLC Genomics Server to read and write to on the server machine' system.
This means that users logged into the CLC Genomics Server from their Workbench will be able to access files in that area, and potentially write files to that area. Note that the CLC Genomics Server will be accessing the file system as the user running the server process - not as the user logged into the Workbench. This means that you should be careful when opening access to the server filesystem in this way. Thus, only folders that do not contain sensitive information should be added.
Folders to be added for this type of access are configured in the web administration interface Admin tab. Under Main configuration, open the Import/export directories (Figure 2.6) to list and/or add directories.
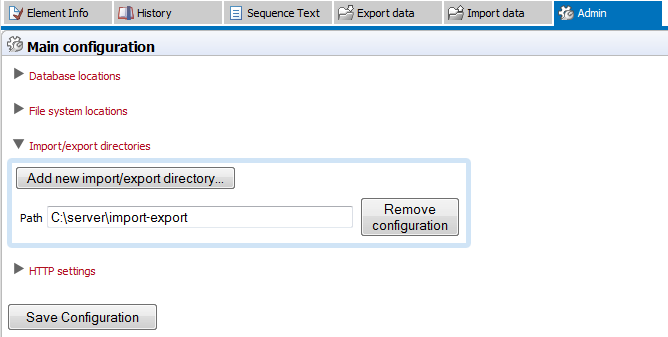
Figure 2.6: Defining source folders that should be available for browsing from the Workbench.
Press the Add new import/export directory button to specify a path to a folder on the server. This folder and all its subfolders will then be available for browsing in the Workbench for certain activities (e.g. importing data functions).
The import/export directories can be accessed from the Workbench via the Import function in the Workbench (Figure 2.5). If a user, that is logged into the CLC Genomics Server via their CLC Workbench, wishes to import e.g. high throughput sequencing data, an the option shown in figure 2.7 will appear.
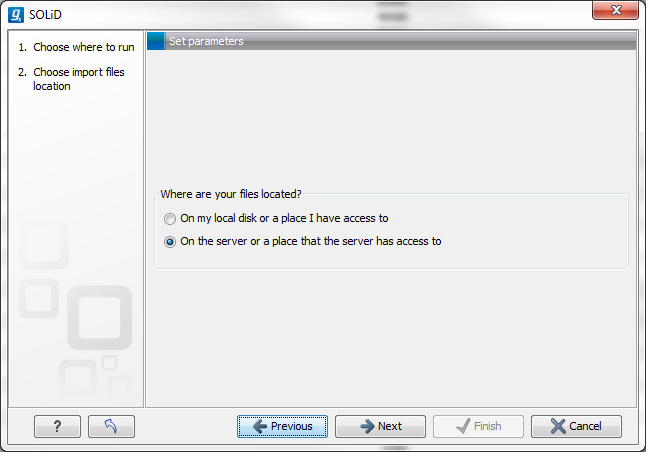
Figure 2.7: Deciding source for high-throughput sequencing data files.
On my local disk or a place I have access to means that the user will be able to select files from the file system of the machine their CLC Workbench is installed on. These files will then be transferred over the network to the server and placed as temporary files for importing. If the user chooses instead the option On the server or a place the server has access to, the user is presented with a file browser for the selected parts of the server file system that the administator has configured as an Import/export location (Figure 2.8).
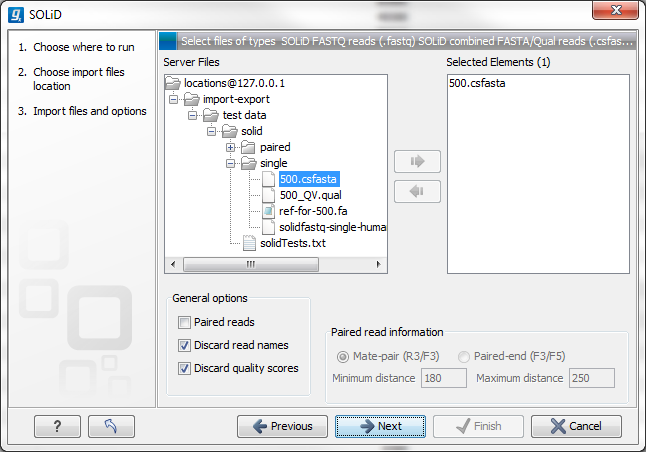
Figure 2.8: Selecting files on server file system.
Note: Import/Export locations should NOT be set to subfolders of any defined CLC file or data location. CLC file and data locations should be used for CLC data, and data should only be added or removed from these areas by CLC tools. By definition, an Import/Export folder is meant for holding non-CLC data, for example, sequencing data that will be imported, data that you export from the Genomics Server, or blast databases. Note that your server administrator needs to configure the server to import files directly from the server file system.