RNA-Seq analysis
Two tools are available for RNA-seq analysis, the tool RNA-Seq Analysis and the tool Create Fold Change Track Based on an annotated reference genome, the Biomedical Genomics Workbench supports RNA-Seq analysis by mapping next-generation sequencing reads and counting and distributing the reads across genes and transcripts. Subsequently, the results can be used for expression analysis using the tools in the Transcriptomics Analysis toolbox.
The tool for RNA-Seq analysis can be found here:
Toolbox | Transcriptomics Analysis (![]() ) | RNA-Seq Analysis (
) | RNA-Seq Analysis (![]() )
)
The approach taken by the Biomedical Genomics Workbench is based on [Mortazavi et al., 2008].
The following describes the overall process of the RNA-Seq analysis when using an annotated eukaryote genome. See Specifying reads, reference genome and mapping settings for more information on other types of reference data.
The RNA-Seq analysis is done in several steps: First, all genes are extracted from the reference genome (using a gene track). Next, all annotated transcripts are extracted (using an mRNA track). If there are several annotated splice variants, they are all extracted.
An example is shown in figure 28.1.

Figure 28.1: A simple gene with three exons and two splice variants.
This is a simple gene with three exons and two splice variants. The transcripts are extracted as shown in figure 28.2.

Figure 28.2: All the exon-exon junctions are joined in the extracted transcript.
Next, the reads are mapped against all the transcripts plus the entire gene (see figure 28.3) and optionally to the whole genome.
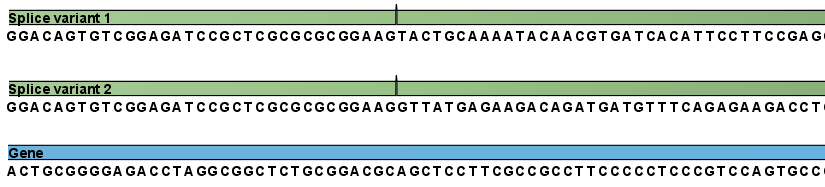
Figure 28.3: The reference for mapping: all the exon-exon junctions and the gene.
From this mapping, the reads are categorized and assigned to the genes (elaborated later in this section), and expression values for each gene and each transcript are calculated.
Details on the process are elaborated in the following sections, which describe how to run RNA-seq analyses.
Subsections
- Specifying reads and reference
- Tightly packed genes and genes in operons
- Defining mapping options for RNA-Seq
- Calculating expression values from RNA-Seq
- Specifying RNA-Seq outputs
- Interpreting the RNA-Seq analysis result
- Create fold change track