To start the clustering of features:
Toolbox | Transcriptomics Analysis (![]() )| Feature Clustering | Hierarchical Clustering of Features (
)| Feature Clustering | Hierarchical Clustering of Features (![]() )
)
Select at least two samples ( (![]() ) or (
) or (![]() )) or an experiment (
)) or an experiment (![]() ).
).
Note! If your data contains many features, the clustering will take very long time and could make your computer unresponsive. It is recommended to perform this analysis on a subset of the data (which also makes it easier to make sense of the clustering. Typically, you will want to filter away the features that are thought to represent only noise, e.g. those with mostly low values, or with little difference between the samples). See how to create a sub-experiment in Creating sub-experiment from selection.
Clicking Next will display a dialog as shown in figure 27.87. The hierarchical clustering algorithm requires that you specify a distance measure and a cluster linkage. The distance measure is used specify how distances between two features should be calculated. The cluster linkage specifies how you want the distance between two clusters, each consisting of a number of features, to be calculated.
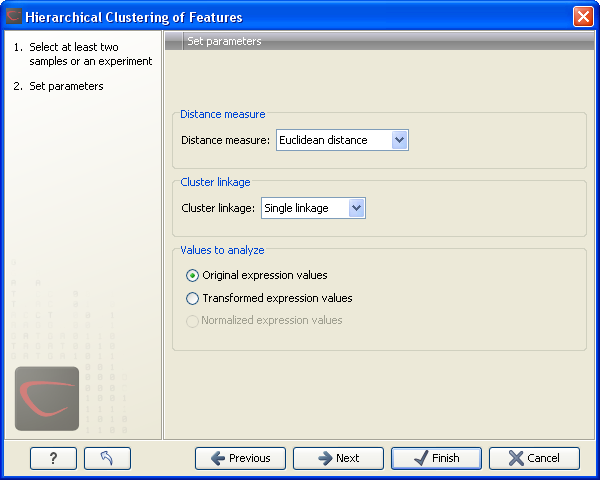
Figure 27.87: Parameters for hierarchical clustering of features.
At the top, you can choose three kinds of Distance measures:
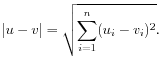
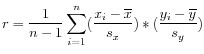
where
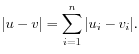
Next, you can select different ways to calculate distances between clusters. The possible cluster linkage to use are:
At the bottom, you can select which values to cluster (see Selecting transformed and normalized values for analysis). Click Next if you wish to adjust how to handle the results. If not, click Finish.